



✍ Posted by Immersive Builder Seong
1. Prometheus Stack
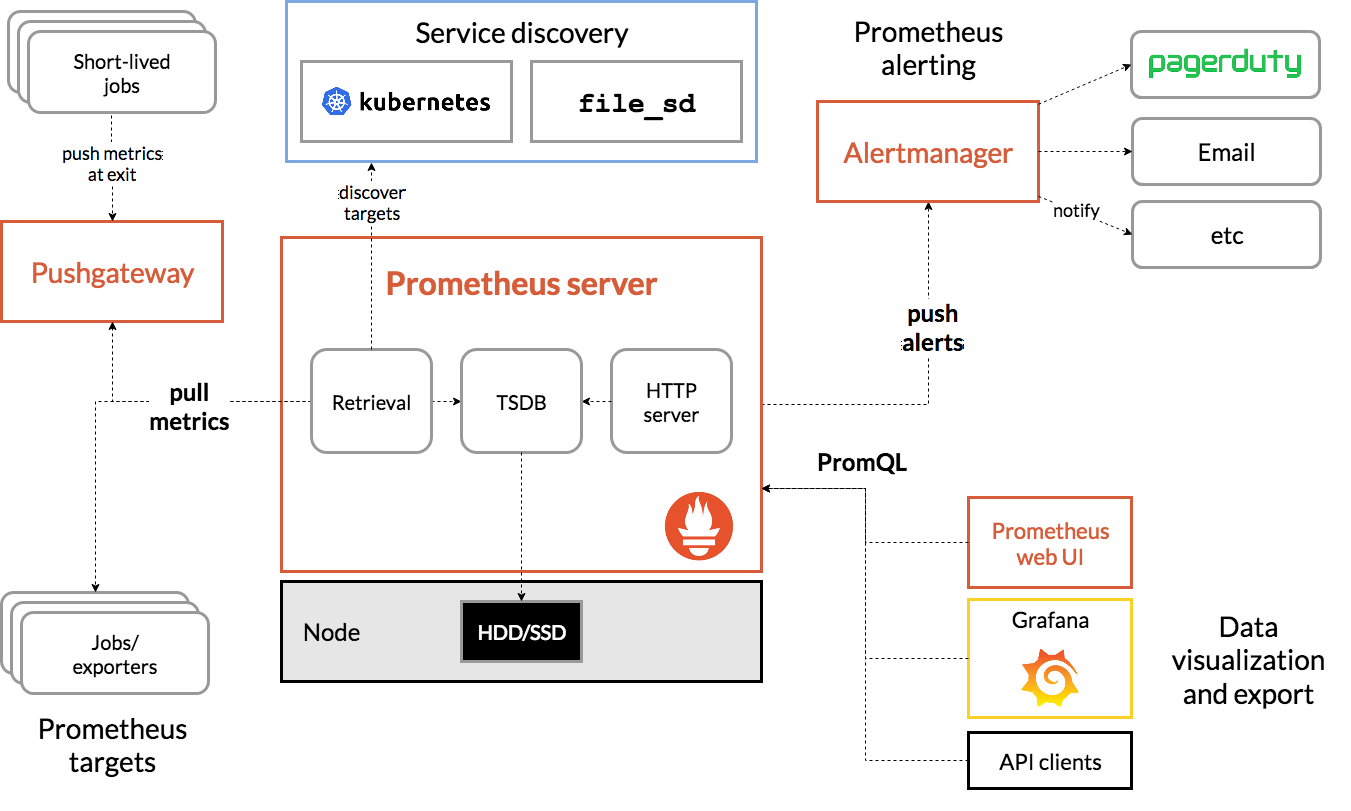
Prometheus 란?
오픈 소스 기반의 시스템 모니터링 및 알람 도구입니다.
- 다차원 데이터 모델 : 시계열 데이터를 저장(TSDB)하며 다양한 차원에서 데이터를 쿼리하고 필터링할 수 있습니다.
- PromQL : Prometheus Query Language, 시계열 데이터베이스에서 데이터를 쿼리하고 분석하기 위한 언어입니다.
- 분산 저장소에 의존하지 않고, 단일 서버 노드가 자체적으로 동작합니다.
- Pull 모델 방식 : Prometheus 서버가 노드에 주기적으로 요청하여 데이터를 가져옵니다. 데이터 수집은 HTTP 요청으로 이루어집니다.
- 중계 게이트웨이 : 시계열 데이터를 전송함에 있어 송신자와 수신자 간에 중계 게이트웨이가 존재합니다.
- Service Discovery 기능을 사용하여 대상을 자동으로 발견하거나 Static Configuration 설정으로 대상을 수동으로 구성할 수 있습니다.
- 시각화를 위한 다양한 그래픽 모드(선그래프, 막대그래프, 파이차트 등)와 대시보드 템플릿을 지원합니다.
하기 명령어로 프로메테우스에서 수집할 수 있는 컨트롤플레인의 메트릭 정보 리스트를 확인할 수 있습니다.
$ kubectl get --raw /metrics | more
```
aggregator_unavailable_apiservice{name="v1."} 0
aggregator_unavailable_apiservice{name="v1.admissionregistration.k8s.io"} 0
aggregator_unavailable_apiservice{name="v1.apiextensions.k8s.io"} 0
```
Prometheus Stack 이란?
Prometheus, Prometheus Alertmanager, Prometheus Rules, Grafana, PromQL 등 모니터링에 필요한 여러 요소를 함께 구성한 것을 의미합니다.
그럼 바로 설치하고 구성해봅시다.
# 네임스페이스 생성
$ kubectl create ns monitoring
namespace/monitoring created
# 모니터링
$ watch kubectl get pod,pvc,svc,ingress -n monitoring
NAME READY STATUS RESTARTS AGE
pod/kube-prometheus-stack-grafana-0 3/3 Running 0 3m58s
pod/kube-prometheus-stack-kube-state-metrics-69d546c6c-2pcjq 1/1 Running 0 3m58s
pod/kube-prometheus-stack-operator-85558c88cb-dh5zd 1/1 Running 0 3m58s
pod/kube-prometheus-stack-prometheus-node-exporter-5cp42 1/1 Running 0 3m58s
pod/kube-prometheus-stack-prometheus-node-exporter-78b8v 1/1 Running 0 3m58s
pod/kube-prometheus-stack-prometheus-node-exporter-xz69c 1/1 Running 0 3m58s
pod/prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 3m52s
NAME STATUS VOLUME
CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/prometheus-kube-prometheus-stack-prometheus-db-prometheus-kube-prometheus-stack-prometheus-0 Bound pvc-1df6dc79-5640-
4cf8-9b0f-4377fecc2f80 30Gi RWO gp3 3m52s
persistentvolumeclaim/storage-kube-prometheus-stack-grafana-0 Bound pvc-387b3bb1-b035-
48a7-9fe8-4e3a42a85008 20Gi RWO gp3 3m58s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-grafana ClusterIP 10.100.87.161 <none> 80/TCP 3m58s
service/kube-prometheus-stack-grafana-headless ClusterIP None <none> 9094/TCP 3m58s
service/kube-prometheus-stack-kube-state-metrics ClusterIP 10.100.152.35 <none> 8080/TCP 3m58s
service/kube-prometheus-stack-operator ClusterIP 10.100.92.175 <none> 443/TCP 3m58s
service/kube-prometheus-stack-prometheus ClusterIP 10.100.86.95 <none> 9090/TCP,8080/TCP 3m58s
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 10.100.87.116 <none> 9100/TCP 3m58s
service/prometheus-operated ClusterIP None <none> 9090/TCP 3m52s
NAME CLASS HOSTS ADDRESS
PORTS AGE
ingress.networking.k8s.io/kube-prometheus-stack-grafana alb grafana.okms1017.name myeks-ingress-alb-650648305.ap-northeast-2.elb.a
mazonaws.com 80 3m58s
ingress.networking.k8s.io/kube-prometheus-stack-prometheus alb prometheus.okms1017.name myeks-ingress-alb-650648305.ap-northeast-2.elb.a
mazonaws.com 80 3m58s
# 인증서 ARN 설정
$ CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
# Repository 추가
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# Prometheus Stack 배포
$ cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: gp3
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
persistence:
enabled: true
type: sts
storageClassName: "gp3"
accessModes:
- ReadWriteOnce
size: 20Gi
defaultRules:
create: false
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
alertmanager:
enabled: false
EOT
# 메트릭 수집주기: 15s
$ helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 57.1.0 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring
NAME: kube-prometheus-stack
LAST DEPLOYED: Sun Mar 31 02:31:57 2024
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=kube-prometheus-stack"
$ helm list -n monitoring
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prometheus-stack monitoring 1 2024-03-31 02:31:57.747634069 +0900 KST deployed kube-prometheus-stack-57.1.0 v0.72.0
$ kubectl get pod,svc,ingress,pvc -n monitoring
NAME READY STATUS RESTARTS AGE
pod/kube-prometheus-stack-grafana-0 3/3 Running 0 62s
pod/kube-prometheus-stack-kube-state-metrics-69d546c6c-2pcjq 1/1 Running 0 62s
pod/kube-prometheus-stack-operator-85558c88cb-dh5zd 1/1 Running 0 62s
pod/kube-prometheus-stack-prometheus-node-exporter-5cp42 1/1 Running 0 62s
pod/kube-prometheus-stack-prometheus-node-exporter-78b8v 1/1 Running 0 62s
pod/kube-prometheus-stack-prometheus-node-exporter-xz69c 1/1 Running 0 62s
pod/prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 56s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-grafana ClusterIP 10.100.87.161 <none> 80/TCP 62s
service/kube-prometheus-stack-grafana-headless ClusterIP None <none> 9094/TCP 62s
service/kube-prometheus-stack-kube-state-metrics ClusterIP 10.100.152.35 <none> 8080/TCP 62s
service/kube-prometheus-stack-operator ClusterIP 10.100.92.175 <none> 443/TCP 62s
service/kube-prometheus-stack-prometheus ClusterIP 10.100.86.95 <none> 9090/TCP,8080/TCP 62s
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 10.100.87.116 <none> 9100/TCP 62s
service/prometheus-operated ClusterIP None <none> 9090/TCP 56s
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress.networking.k8s.io/kube-prometheus-stack-grafana alb grafana.okms1017.name myeks-ingress-alb-650648305.ap-northeast-2.elb.amazonaws.com 80 62s
ingress.networking.k8s.io/kube-prometheus-stack-prometheus alb prometheus.okms1017.name myeks-ingress-alb-650648305.ap-northeast-2.elb.amazonaws.com 80 62s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/prometheus-kube-prometheus-stack-prometheus-db-prometheus-kube-prometheus-stack-prometheus-0 Bound pvc-1df6dc79-5640-4cf8-9b0f-4377fecc2f80 30Gi RWO gp3 56s
persistentvolumeclaim/storage-kube-prometheus-stack-grafana-0 Bound pvc-387b3bb1-b035-48a7-9fe8-4e3a42a85008 20Gi RWO gp3 62s
$ kubectl get-all -n monitoring
$ kubectl get prometheus,servicemonitors -n monitoring
NAME VERSION DESIRED READY RECONCILED AVAILABLE AGE
prometheus.monitoring.coreos.com/kube-prometheus-stack-prometheus v2.51.0 1 1 True True 2m4s
NAME AGE
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-apiserver 2m4s
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-coredns 2m4s
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-grafana 2m4s
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-proxy 2m4s
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-state-metrics 2m4s
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kubelet 2m4s
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-operator 2m4s
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-prometheus 2m4s
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-prometheus-node-exporter 2m4s
$ kubectl get crd | grep monitoring
alertmanagerconfigs.monitoring.coreos.com 2024-03-30T17:31:53Z
alertmanagers.monitoring.coreos.com 2024-03-30T17:31:53Z
podmonitors.monitoring.coreos.com 2024-03-30T17:31:54Z
probes.monitoring.coreos.com 2024-03-30T17:31:54Z
prometheusagents.monitoring.coreos.com 2024-03-30T17:31:54Z
prometheuses.monitoring.coreos.com 2024-03-30T17:31:55Z
prometheusrules.monitoring.coreos.com 2024-03-30T17:31:55Z
scrapeconfigs.monitoring.coreos.com 2024-03-30T17:31:56Z
servicemonitors.monitoring.coreos.com 2024-03-30T17:31:56Z
thanosrulers.monitoring.coreos.com 2024-03-30T17:31:56Z
$ kubectl df-pv
PV NAME PVC NAME NAMESPACE NODE NAME POD NAME VOLUME MOUNT NAME SIZE USED AVAILABLE %USED IUSED IFREE %IUSED
pvc-387b3bb1-b035-48a7-9fe8-4e3a42a85008 storage-kube-prometheus-stack-grafana-0 monitoring ip-192-168-3-165.ap-northeast-2.compute.internal kube-prometheus-stack-grafana-0 storage 19Gi 177Mi 19Gi 0.87 11 10485749 0.00
pvc-1df6dc79-5640-4cf8-9b0f-4377fecc2f80 prometheus-kube-prometheus-stack-prometheus-db-prometheus-kube-prometheus-stack-prometheus-0 monitoring ip-192-168-1-85.ap-northeast-2.compute.internal prometheus-kube-prometheus-stack-prometheus-0 prometheus-kube-prometheus-stack-prometheus-db 29Gi 254Mi 29Gi 0.83 9 15728631 0.00
하나의 Ingress에 3개의 대상그룹이 연결된 모습입니다.
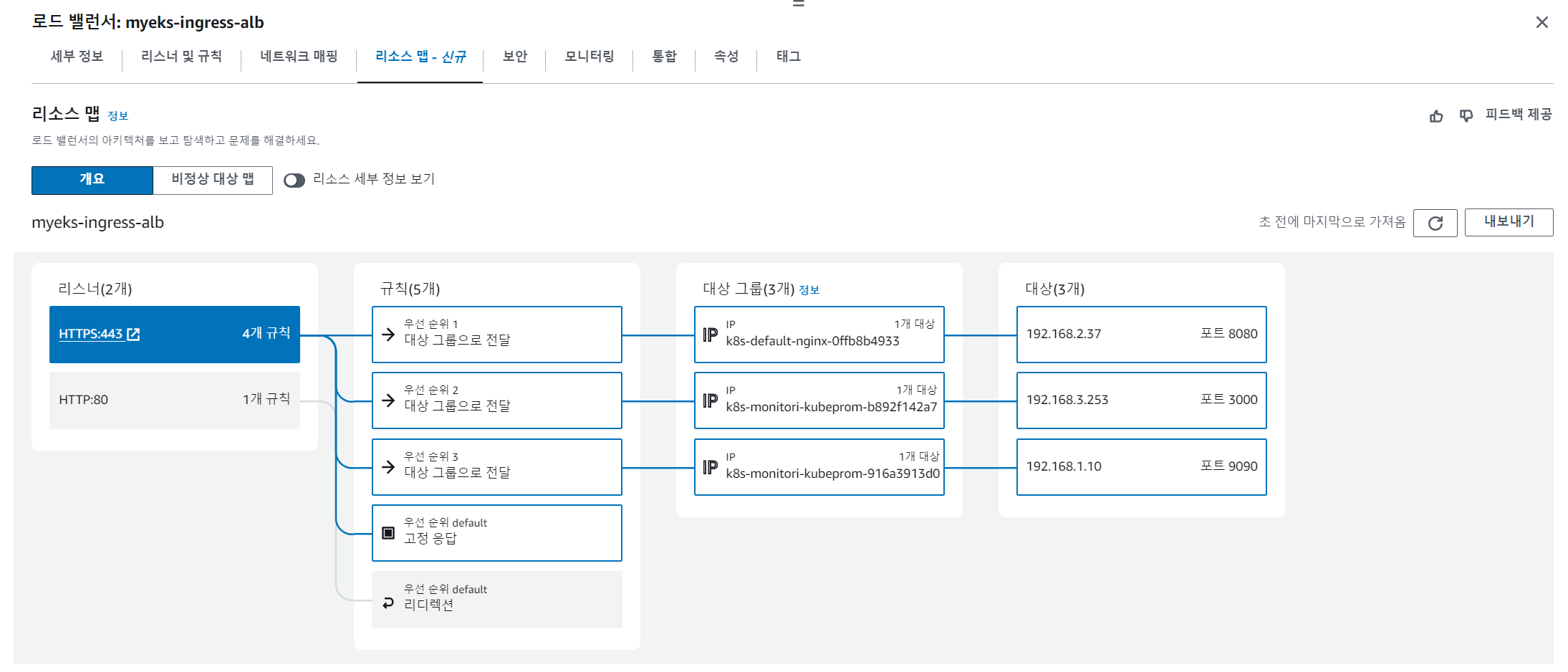
3개의 서비스가 모두 443 포트로 요청을 받지만 호스트 헤더의 도메인 주소값을 보고 분기하고 있습니다.

왜냐하면 Nginx, Prometheus, Grafana 배포 시, 두 가지 어노테이션을 동일하게 주었기 때문입니다.
- alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
- alb.ingress.kubernetes.io/group.name: study

* PodMonitor 란?
- Prometheus Operator를 사용하여 파드의 메트릭을 수집하기 위한 Prometheus 리소스 유형입니다.
- Prometheus가 수집하는 파드 수준의 메트릭을 정의하고 선택적으로 레이블 셀렉터를 사용하여 수집할 파드를 지정합니다.
PodMonitor를 배포하여 AWS CNI 메트릭을 수집해봅시다.
배포한 후 메트릭이 충분히 수집될 때까지 30분 정도 기다려줍니다.
# PodMonitor 배포
$ cat <<EOF | kubectl create -f -
> apiVersion: monitoring.coreos.com/v1
> kind: PodMonitor
> metadata:
> name: aws-cni-metrics
> namespace: kube-system
> spec:
> jobLabel: k8s-app
> namespaceSelector:
> matchNames:
> - kube-system
> podMetricsEndpoints:
> - interval: 30s
> path: /metrics
> port: metrics
> selector:
> matchLabels:
> k8s-app: aws-node
> EOF
podmonitor.monitoring.coreos.com/aws-cni-metrics created
$ kubectl get podmonitor -n kube-system
NAME AGE
aws-cni-metrics 10s
$ kubectl get podmonitor -n kube-system aws-cni-metrics -o yaml | kubectl neat
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
# Metrics URL 접속 확인
$ curl -s $N1:61678/metrics | grep '^awscni'
awscni_add_ip_req_count 10
awscni_assigned_ip_addresses 7
awscni_assigned_ip_per_cidr{cidr="192.168.1.10/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.138/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.143/32"} 0
awscni_assigned_ip_per_cidr{cidr="192.168.1.169/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.208/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.231/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.249/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.68/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.89/32"} 0
awscni_assigned_ip_per_eni{eni="eni-0aa1a1ab6d1f441d1"} 0
awscni_assigned_ip_per_eni{eni="eni-0ad104c85976d40ce"} 7
awscni_aws_api_latency_ms_sum{api="AssignPrivateIpAddresses",error="false",status="200"} 395
awscni_aws_api_latency_ms_count{api="AssignPrivateIpAddresses",error="false",status="200"} 1
awscni_aws_api_latency_ms_sum{api="AttachNetworkInterface",error="false",status="200"} 753
awscni_aws_api_latency_ms_count{api="AttachNetworkInterface",error="false",status="200"} 1
awscni_aws_api_latency_ms_sum{api="CreateNetworkInterface",error="false",status="200"} 437
awscni_aws_api_latency_ms_count{api="CreateNetworkInterface",error="false",status="200"} 1
awscni_aws_api_latency_ms_sum{api="CreateTags",error="false",status="200"} 192
awscni_aws_api_latency_ms_count{api="CreateTags",error="false",status="200"} 1
awscni_aws_api_latency_ms_sum{api="DescribeInstances",error="false",status="200"} 127
awscni_aws_api_latency_ms_count{api="DescribeInstances",error="false",status="200"} 1
awscni_aws_api_latency_ms_sum{api="DescribeNetworkInterfaces",error="false",status="200"} 242
awscni_aws_api_latency_ms_count{api="DescribeNetworkInterfaces",error="false",status="200"} 1
awscni_aws_api_latency_ms_sum{api="GetMetadata",error="false",status="200"} 1808
awscni_aws_api_latency_ms_count{api="GetMetadata",error="false",status="200"} 7223
awscni_aws_api_latency_ms_sum{api="GetMetadata",error="true",status="404"} 140
awscni_aws_api_latency_ms_count{api="GetMetadata",error="true",status="404"} 961
awscni_aws_api_latency_ms_sum{api="ModifyNetworkInterfaceAttribute",error="false",status="200"} 775
awscni_aws_api_latency_ms_count{api="ModifyNetworkInterfaceAttribute",error="false",status="200"} 2
awscni_aws_api_latency_ms_sum{api="waitForENIAndIPsAttached",error="false",status="200"} 3311
awscni_aws_api_latency_ms_count{api="waitForENIAndIPsAttached",error="false",status="200"} 1
awscni_build_info{goversion="go1.21.8",version=""} 1
awscni_del_ip_req_count{reason="PodDeleted"} 9
awscni_ec2api_req_count{fn="AssignPrivateIpAddresses"} 1
awscni_ec2api_req_count{fn="AttachNetworkInterface"} 1
awscni_ec2api_req_count{fn="CreateNetworkInterface"} 1
awscni_ec2api_req_count{fn="CreateTags"} 1
awscni_ec2api_req_count{fn="DescribeInstances"} 1
awscni_ec2api_req_count{fn="DescribeNetworkInterfaces"} 9
awscni_ec2api_req_count{fn="ModifyNetworkInterfaceAttribute"} 2
awscni_eni_allocated 2
awscni_eni_max 4
awscni_force_removed_enis 0
awscni_force_removed_ips 0
awscni_ip_max 56
awscni_ipamd_action_inprogress{fn="increaseDatastorePool"} 0
awscni_ipamd_action_inprogress{fn="nodeIPPoolReconcile"} 0
awscni_ipamd_action_inprogress{fn="nodeInit"} 0
awscni_no_available_ip_addresses 0
awscni_reconcile_count{fn="eniDataStorePoolReconcileAdd"} 13328
awscni_total_ip_addresses 28
awscni_total_ipv4_prefixes 0
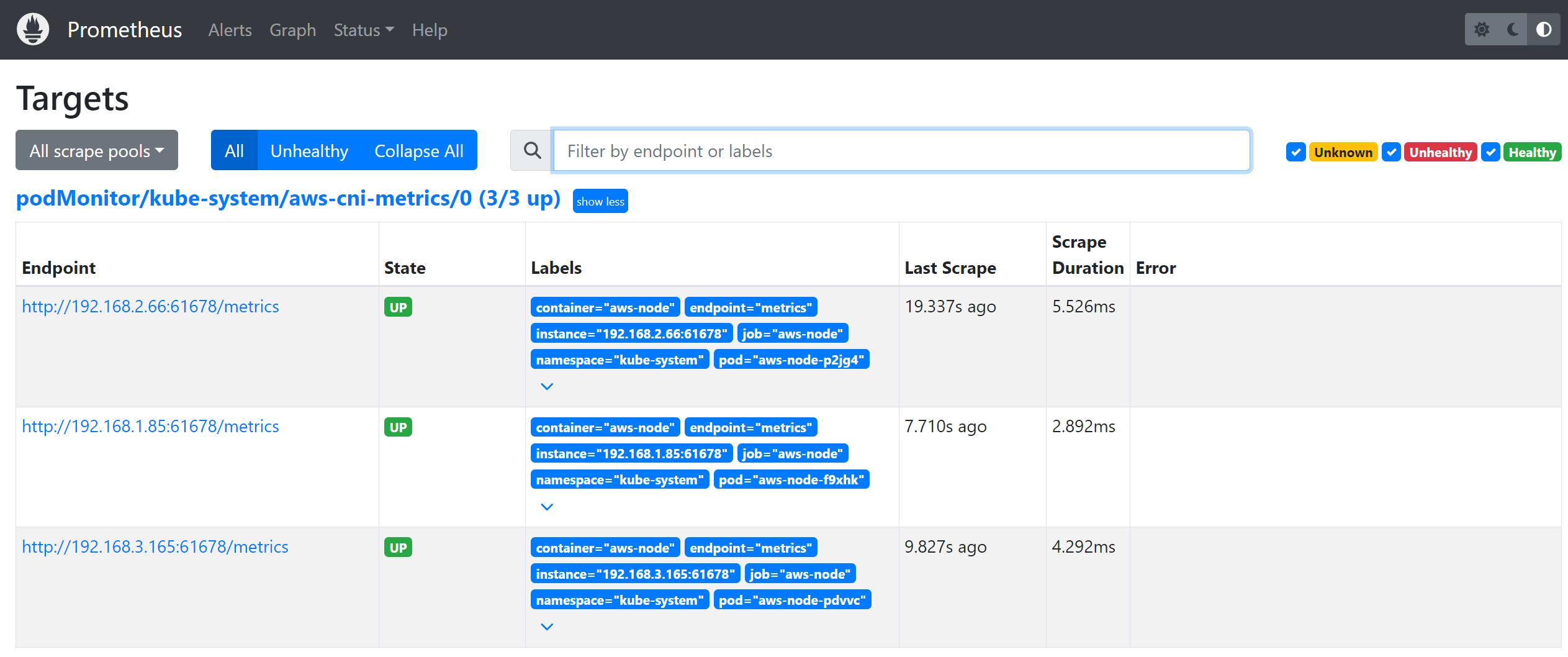
Targets에서 Service Discovery로 자동 등록된 전체 메트릭 대상을 보여줍니다.
AWS CNI 메트릭이 수집된 것을 확인할 수 있습니다.
* ServiceMonitor 란?
- Prometheus Operator를 사용하여 서비스의 메트릭을 수집하기 위한 Prometheus 리소스 유형입니다.
- Prometheus가 수집하는 서비스 수준의 메트릭을 정의하고, 레이블 셀렉터를 사용하여 수집할 서비스를 지정합니다.
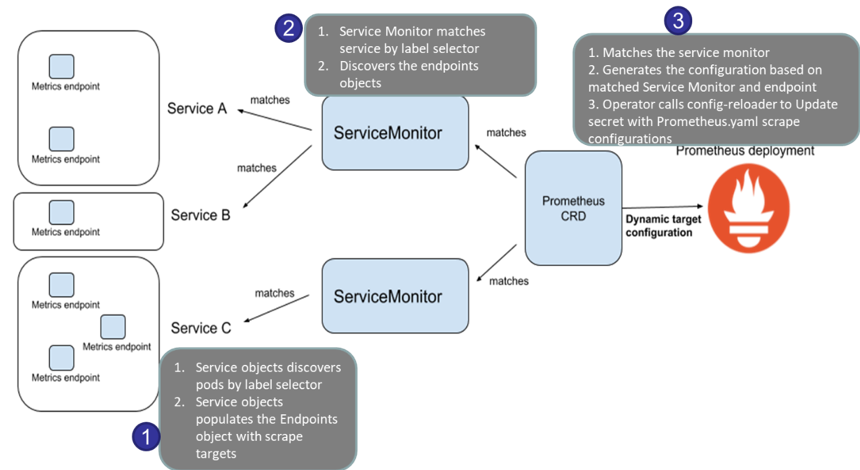
어플리케이션의 메트릭을 수집하기 위해서 ServiceMonitor를 사용합니다.
PodMonitor와 ServiceMonitor 모두 레이블 셀렉터를 사용하기는 하나,
서비스가 파드보다 한 단계 상위 레벨이면서 파드가 동적으로 생성/삭제를 반복할 때 주기적인 헬스체크를 통해 파드의 상태를 이해하기 때문입니다.
따라서 ServiceMonitor가 PodMonitor와 비교하여 어플리케이션 메트릭 수집에 보다 적합합니다.
기본 사용
모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출합니다.
이후 Prometheus는 해당 경로에 HTTP GET 방식으로 메트릭 정보를 가져와 TSDB 형식으로 저장합니다.
$ kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 10.100.87.116 <none> 9100/TCP 48m
NAME ENDPOINTS AGE
endpoints/kube-prometheus-stack-prometheus-node-exporter 192.168.1.85:9100,192.168.2.66:9100,192.168.3.165:9100 48m
# Worker Node: /metrics 정보 확인
$ ssh ec2-user@$N1 curl -s localhost:9100/metrics
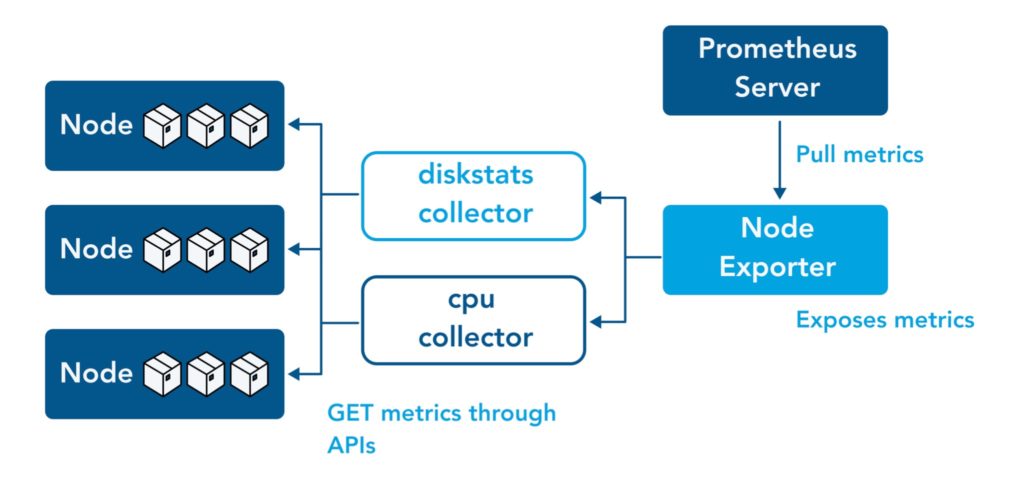
Node exporter는 Worker Node의 시스템 메트릭을 수집하여 Prometheus 서버로 전송하는 창구 역할을 합니다.
디폴트로 '9100' 포트를 사용합니다.

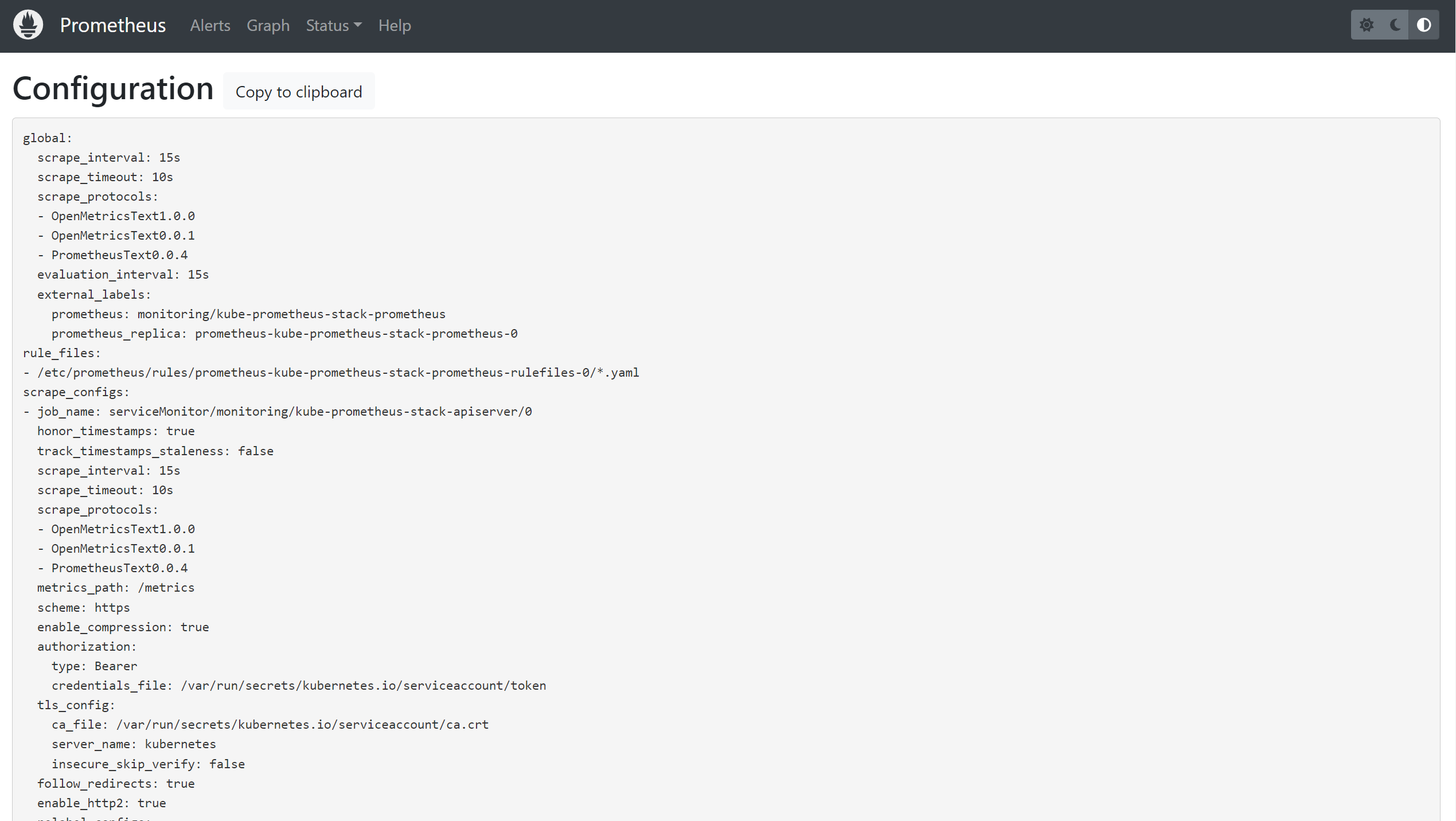
* Configuration : Prometheus 주요 설정 확인
- scrape_interval: 15s # 메트릭 수집 주기
- metrics_path: /metrics # 메트릭 수집 경로
- scheme: http # 프로토콜
- kubernetes_sd_configs: # 서비스 디스커버리 사용
쿼리 조회가 가능하고 Table/Graph 형식으로 결과를 출력할 수 있습니다.
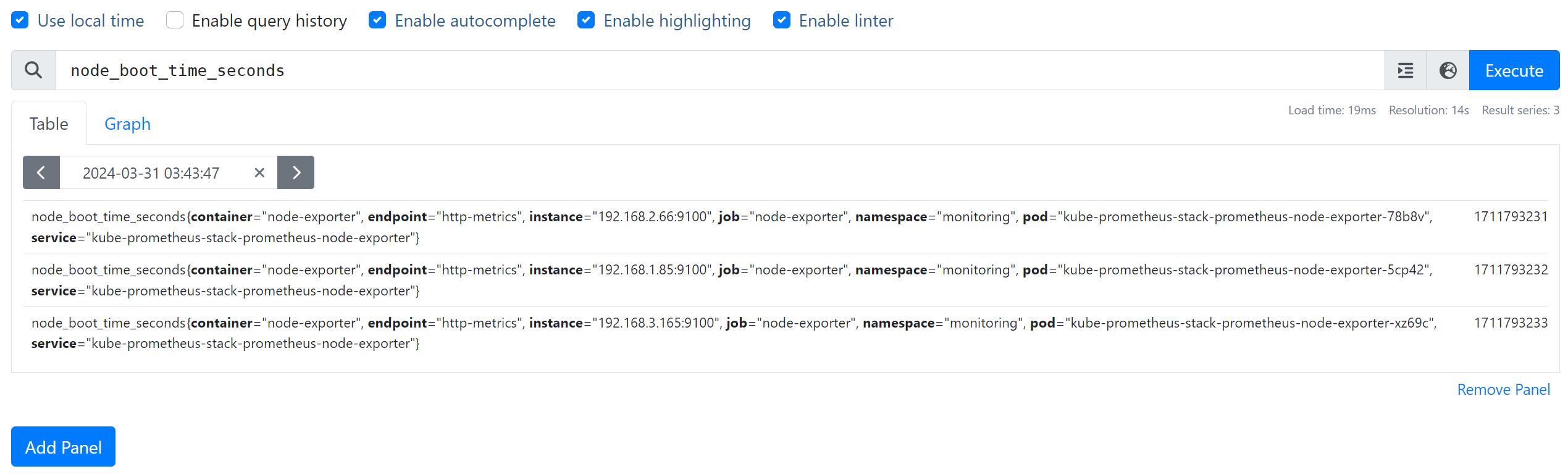

PromQL
Prometheus 메트릭 종류에는 4가지가 있습니다.
- Gauge : 특정 시점의 값을 표현하기 위해서 사용하는 메트릭 타입, CPU 온도나 메모리 사용량에 대한 현재 시점 값
- Counter : 누적된 값을 표현하기 위해 사용하는 메트릭 타입, 증가 시 구간 별로 변화(추세) 확인, 계속 증가 → 함수 등으로 활용
- Summary : 구간 내에 있는 메트릭 값의 빈도, 중앙값 등 통계적 메트릭
- Histogram : 사전에 미리 정의한 구간 내에 있는 메트릭 값의 빈도를 측정 → 함수로 측정 포맷을 변경
신나는 쿼리 연습 시간 :-)
- 특정 노드 필터링 : node_memory_Active_bytes{instance="192.168.3.165:9100"}

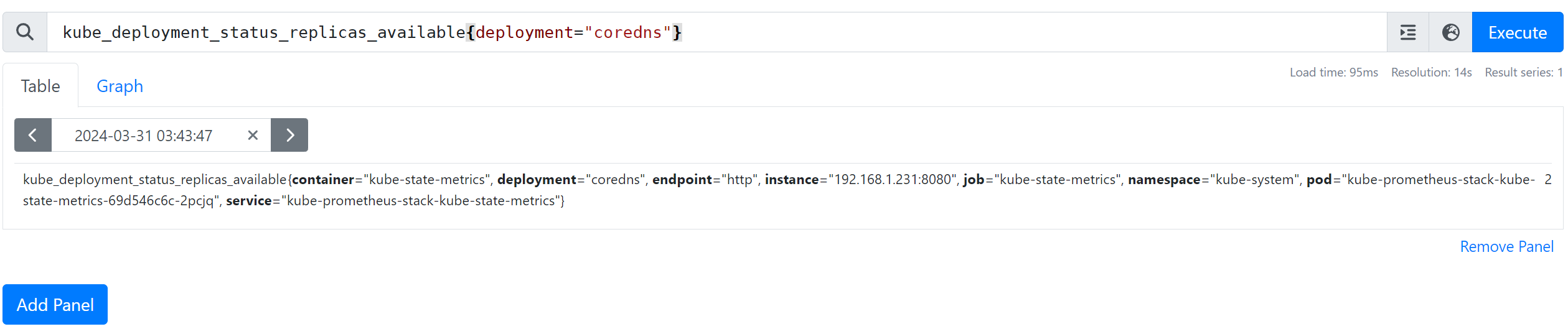
- 특정 디플로이먼트 필터링 : kube_deployment_status_replicas_available{deployment="coredns"}
- 특정 kube-proxy 필터링 : kubeproxy_sync_proxy_rules_iptables_total{table="nat", instance="192.168.3.165:10249"}

어플리케이션 메트릭을 수집하도록 설정한 후 쿼리를 조회해봅시다.
# 모니터링
$ watch -d "kubectl get pod; echo; kubectl get servicemonitors -n monitoring"
# ServiceMonitor
# exporter: Port 9113
$ cat <<EOT > ~/nginx_metric-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# ServiceMonitor 배포
$ helm upgrade nginx bitnami/nginx --reuse-values -f nginx_metric-values.yaml
# 배포 확인
$ kubectl get pod,svc,ep
NAME READY STATUS RESTARTS AGE
pod/nginx-54466cb6f6-swxtv 2/2 Running 0 90s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 9h
service/nginx NodePort 10.100.247.225 <none> 80:31576/TCP,9113:32018/TCP 119m
NAME ENDPOINTS AGE
endpoints/kubernetes 192.168.1.155:443,192.168.3.25:443 9h
endpoints/nginx 192.168.3.121:9113,192.168.3.121:8080 119m
# 메트릭 확인 >> 프로메테우스에서 Target 확인
$ NGINXIP=$(kubectl get pod -l app.kubernetes.io/instance=nginx -o jsonpath={.items[0].status.podIP})
$ curl -s http://$NGINXIP:9113/metrics # nginx_connections_active Y 값 확인해보기
$ curl -s http://$NGINXIP:9113/metrics | grep ^nginx_connections_active
# nginx 파드내에 컨테이너 갯수 확인
$ kubectl get pod -l app.kubernetes.io/instance=nginx
NAME READY STATUS RESTARTS AGE
nginx-54466cb6f6-swxtv 2/2 Running 0 3m24s
$ kubectl describe pod -l app.kubernetes.io/instance=nginx
```
metrics:
Container ID: containerd://c7f37d0fc008e885f4a171aaed1e4088b7610767a2988a947c7ed8fc952ea82b
Image: docker.io/bitnami/nginx-exporter:1.1.0-debian-12-r7
Image ID: docker.io/bitnami/nginx-exporter@sha256:1e726e2586f1c25012cabbdf775feb9c511f7c2a7f7c785316617907f58c3194
Port: 9113/TCP
Host Port: 0/TCP
Command:
exporter
```
# 모니터링
$ kubectl logs deploy/nginx -f
# 웹 서버 접속 시도
$ while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done
ServiceMonitor에 의해 Nginx 어플리케이션 메트릭이 수집되기 시작합니다.
또한, Reloader가 동작하면서 설정이 자동으로 반영이 되고 있습니다.


- nginx_up

- nginx_http_requests_total

- nginx_connections_active

- 특정 노드가 아닌 모든 노드 필터링 : node_memory_Active_bytes{instance!="192.168.3.165:9100"}

- 특정 대역의 노드 필터링 : node_memory_Active_bytes{instance=~"192.168.1.+"}

- 다수의 노드 필터링 : node_memory_Active_bytes{instance=~"192.168.1.85:9100|192.168.2.66:9100"}

- 다수의 노드 제외 필터링 : node_memory_Active_bytes{instance!~"192.168.1.85:9100|192.168.2.66:9100"}

- 특정 네임스페이스의 디플로이먼트 필터링 : kube_deployment_status_replicas_available{namespace="kube-system", deployment="coredns"}

- Byte → MegaByte 단위 변경 : node_memory_Active_bytes/1024/1024
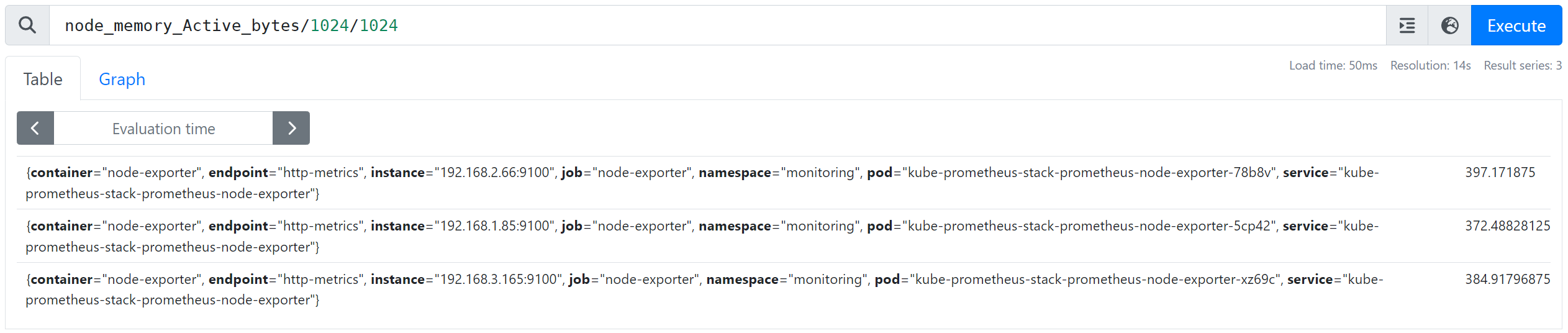
- HTTP 요청 수 1000 이상 필터링 : nginx_http_requests_total > 1000

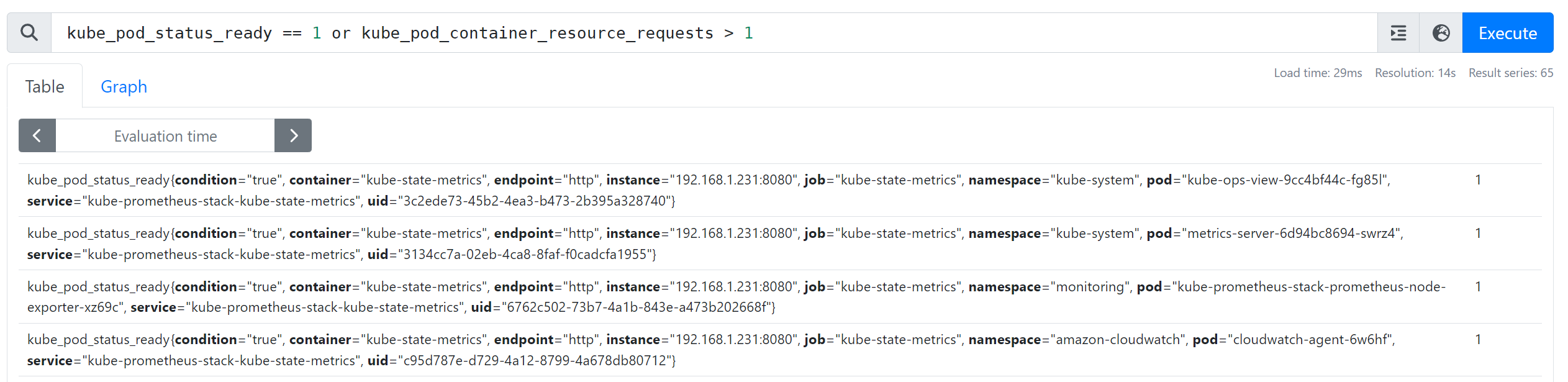
- 다수 조건을 만족하는 경우 : kube_pod_status_ready == 1 or kube_pod_container_resource_requests > 1
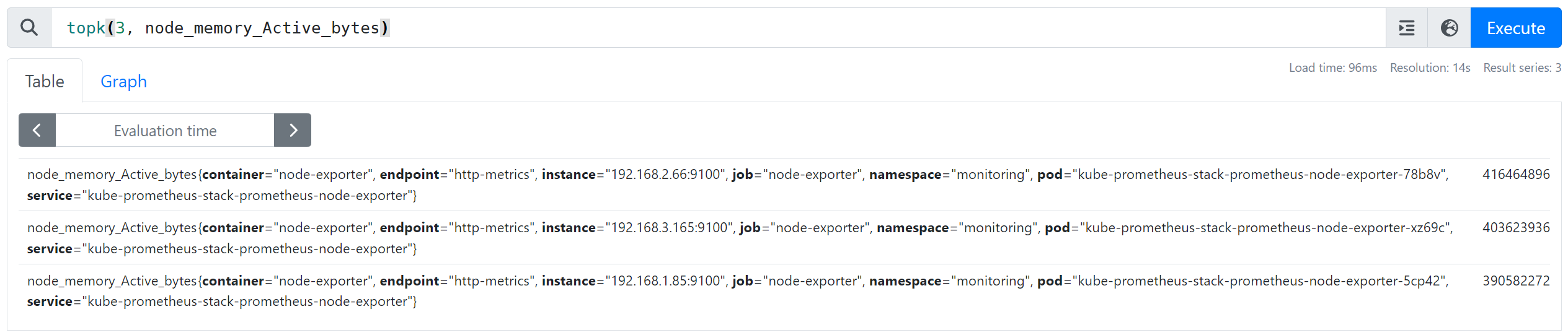
- 노드 메모리 사용률 높은 순(3) 필터링 : topk(3, node_memory_Active_bytes)
- 노드 메모리 사용률 낮은 순(3) 필터링 : bottomk(3, node_memory_Active_bytes>0)

- 노드별 사용자 CPU 평균 사용시간 : avg(node_cpu_seconds_total{mode="user"}) by (instance)

- 노드별 총 HTTP 요청 횟수 : sum(nginx_http_requests_total) by (instance)

- 특정 필드 제외 필터링 : sum(nginx_http_requests_total) without (instance,container,endpoint,job,namespace)

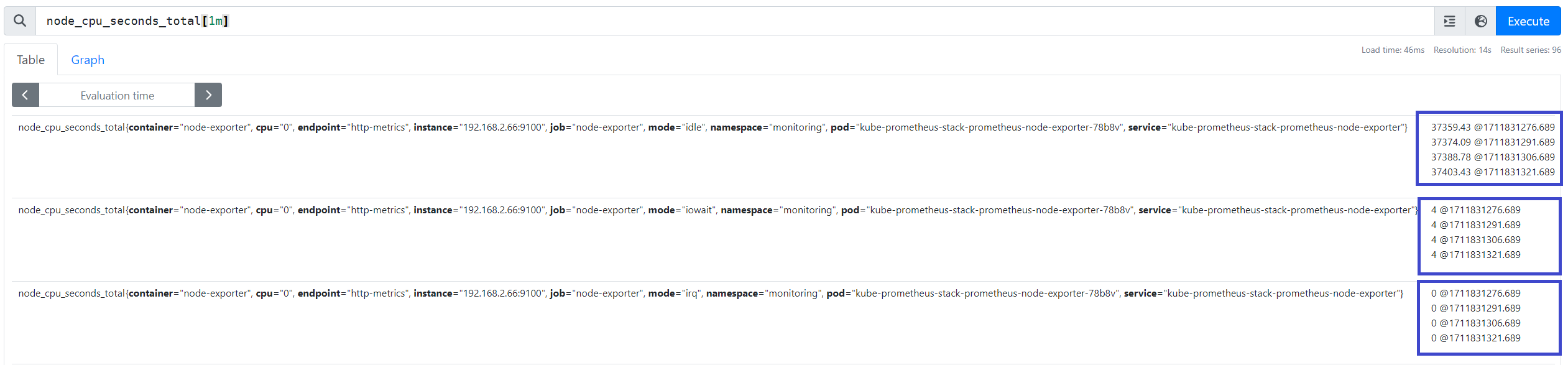
- 시점 데이터 필터링 (4회차/1분) : node_cpu_seconds_total[1m]
- 네임스페이스별 서비스 정보 개수 필터링 : count(kube_service_info) by (namespace)

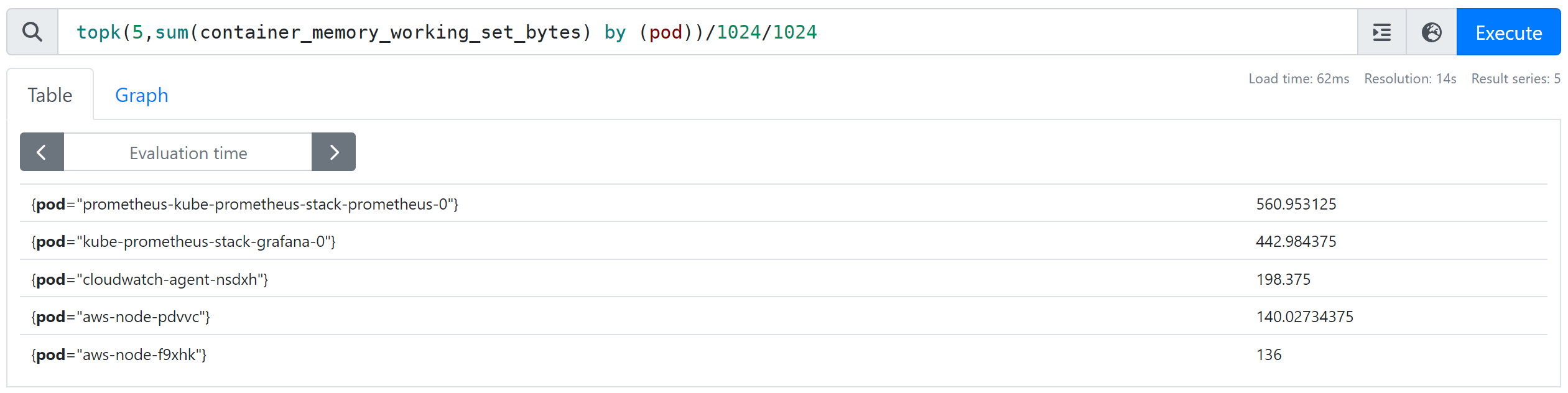
- 파드별 컨테이너 메모리 총 사용량 Top 5(MB) : topk(5,sum(container_memory_working_set_bytes) by (pod))/1024/1024
2. Grafana
Grafana 란?
여러 데이터소스에서 수집한 메트릭 정보를 시각화하고 모니터링할 수 있는 오픈소스 도구입니다.
Prometheus 대시보드에서 표현할 수 있는 그래픽은 한계가 있으므로, Prometheus와 Grafana를 함께 사용하면 좋습니다.
- 다양한 데이터 소스 지원 : Prometheus, ElasticSearch, MySQL, PostgreSQL, InfluxDB 등 메트릭 스토어 또는 데이터베이스와 연동하여 데이터를 가져올 수 있습니다.
- 대시보드 및 시각화 : 대시보드를 생성하고 차트, 그래프, 테이블 등의 시각화 도구를 사용하여 데이터를 시각적으로 표현할 수 있습니다.
- 알림 및 경고 : 사용자가 정의한 조건에 따라 알림을 생성하고 경고를 전송할 수 있는 기능을 제공합니다.
- 사용자 정의 및 확장성 : 다양한 플러그인과 사용자 정의 기능을 제공하여 요구사항에 맞게 커스터마이징이 용이합니다.
- Grafana는 시각화 도구로 데이터 자체를 저장하지 않습니다.

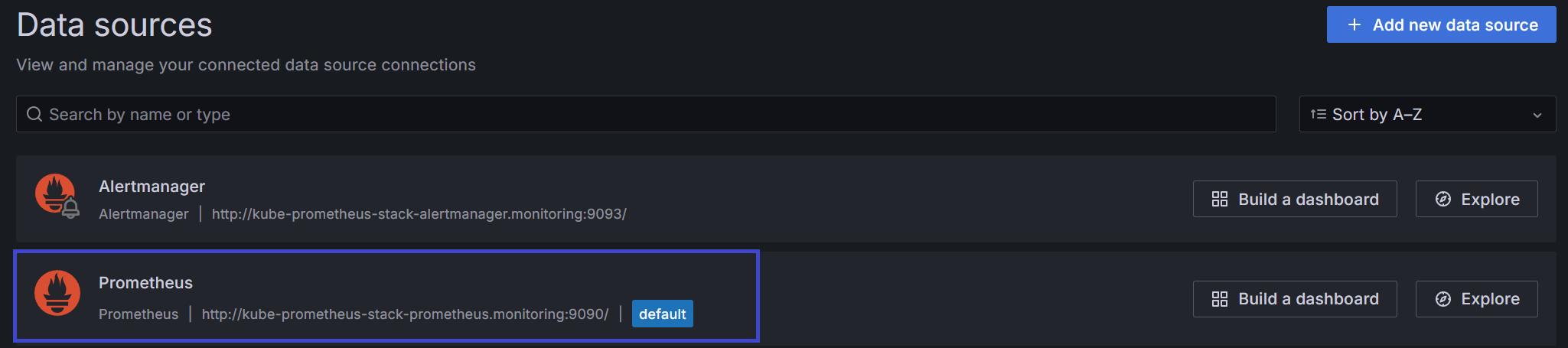
데이터소스에 프로메테우스가 연결되어 있습니다.
# Ingress ALB Endpoint
$ kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-prometheus ClusterIP 10.100.86.95 <none> 9090/TCP,8080/TCP 3h49m
NAME ENDPOINTS AGE
endpoints/kube-prometheus-stack-prometheus 192.168.1.10:9090,192.168.1.10:8080 3h49m

대시보드 템플릿을 가져와서 이쁘게 꾸며봅시다.
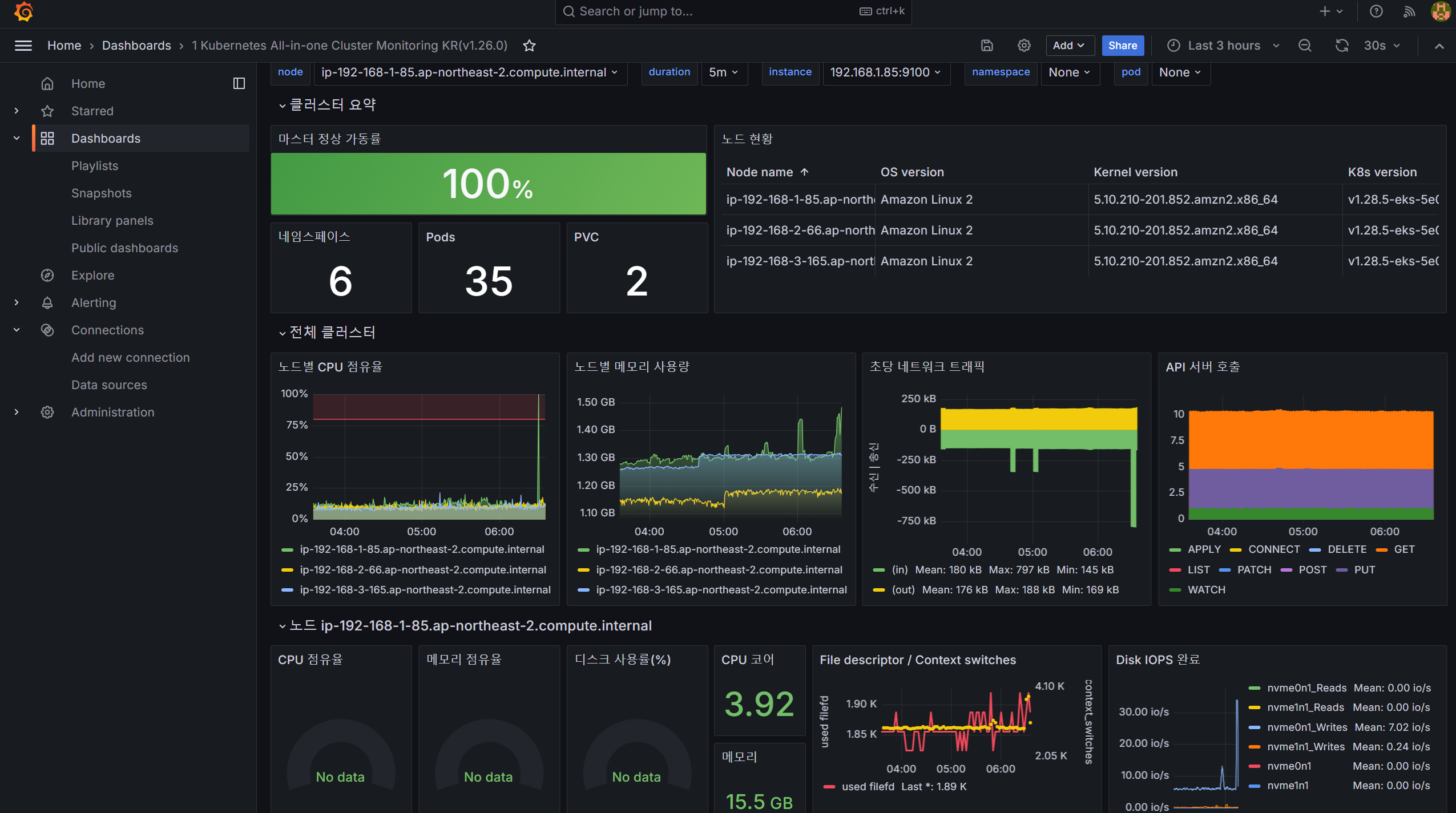
CPU/MEM/DISK 사용률이 비어 있으므로 해당 값이 출력되도록 쿼리를 수정합니다.
패널에 입력하는 쿼리 역시 PromQL 입니다.
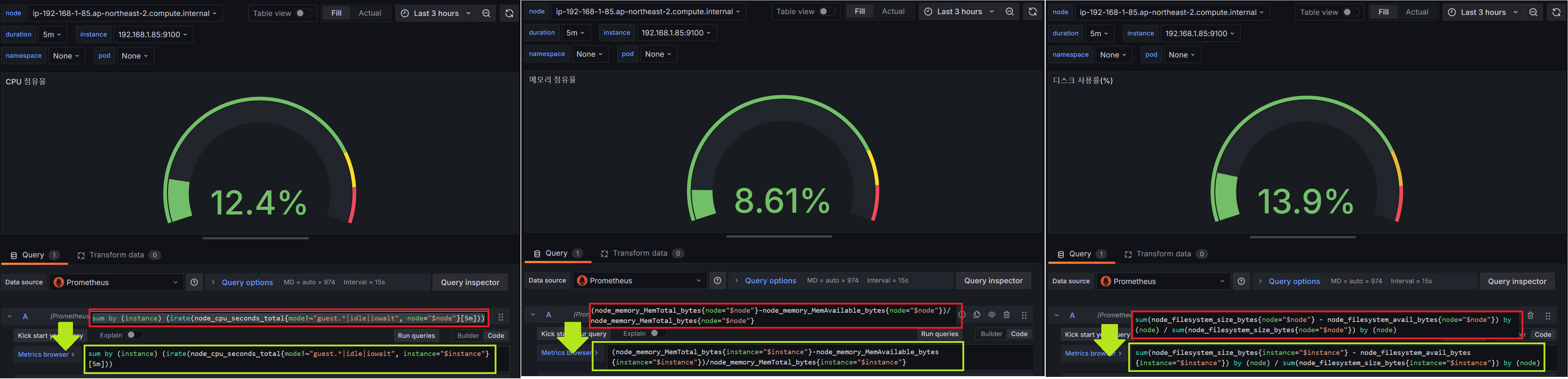
잘 나오고 있네요.
이번에는 Nginx 어플리케이션을 모니터링하기 위한 대시보드를 추가해봅시다.

# Scale-out
$ kubectl scale deployment nginx --replicas 9
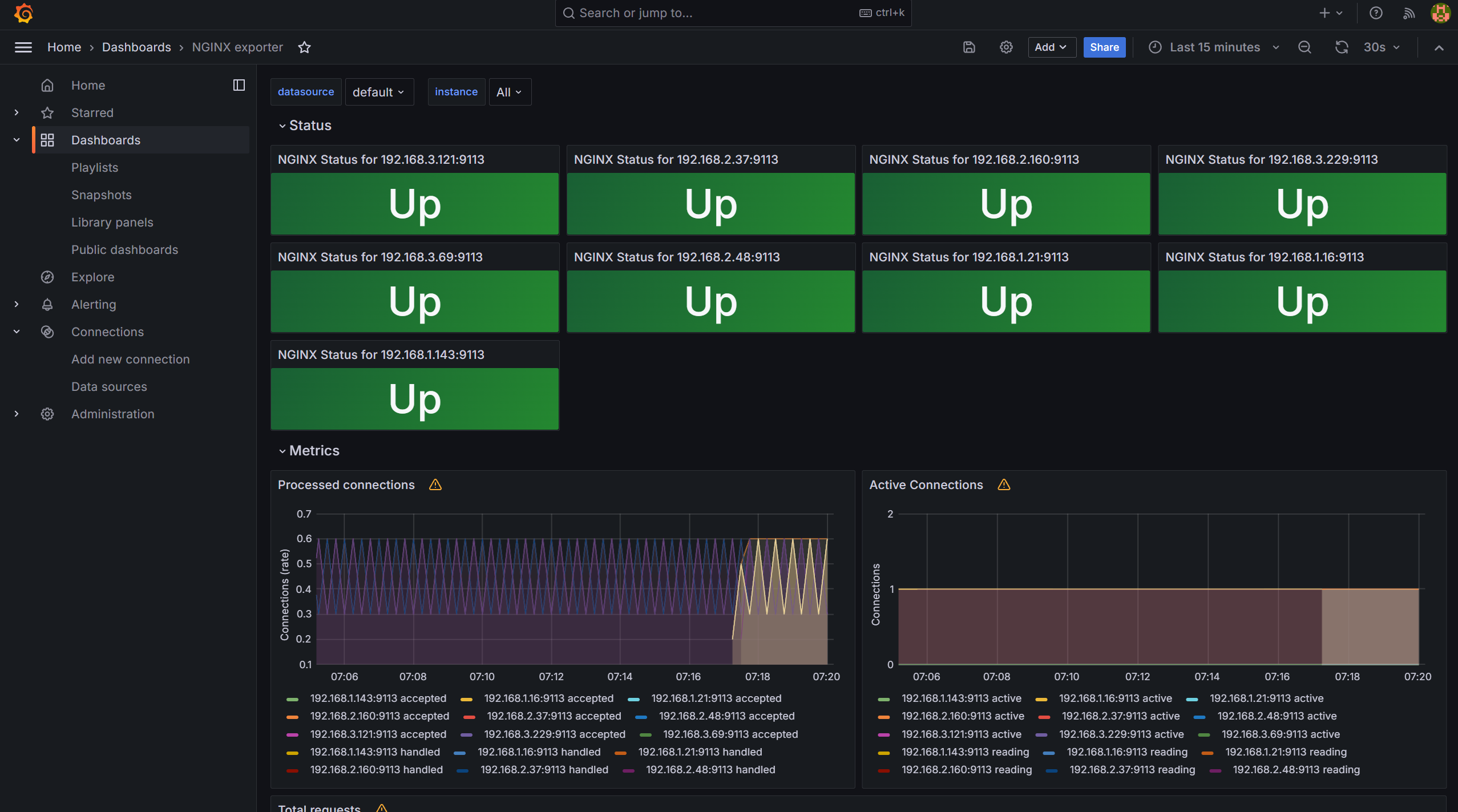
Panels
- Graphs & Charts : Time series, State timeline, Status history, Bar chart, Histogram, Heatmap, Pie chart, Candlestick, Gauge, Trend

- Stats & Big numbers : Stat, Bar gauge(horizontal/vertical), Radial gauge


- Misc : Table, Logs, Node graph, Traces, Flame graph, Canvas, Geomap, Datagrid
- Widgets : Dashboard list, Alert list, Annotations list, Text, News
신규 대시보드를 생성하여 패널을 하나씩 추가해보겠습니다.
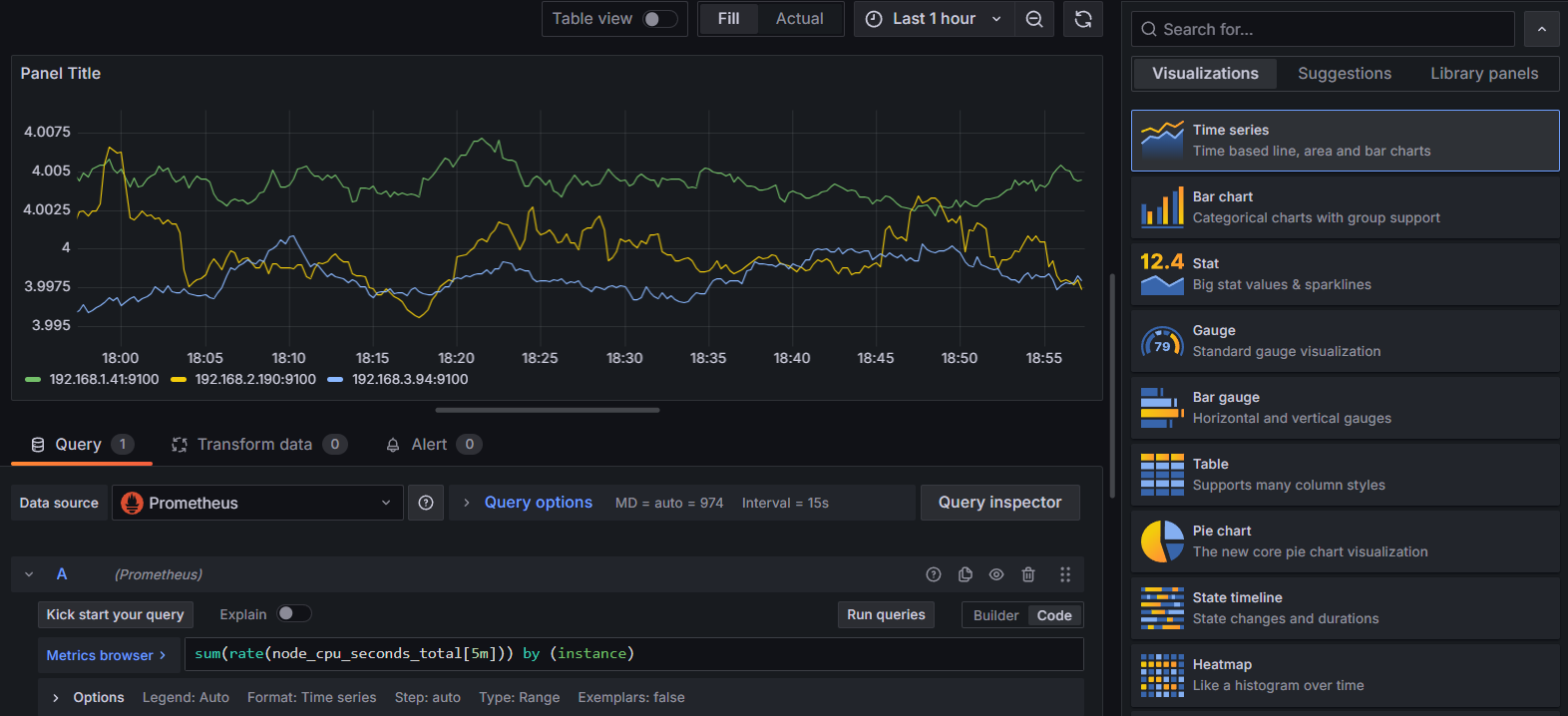
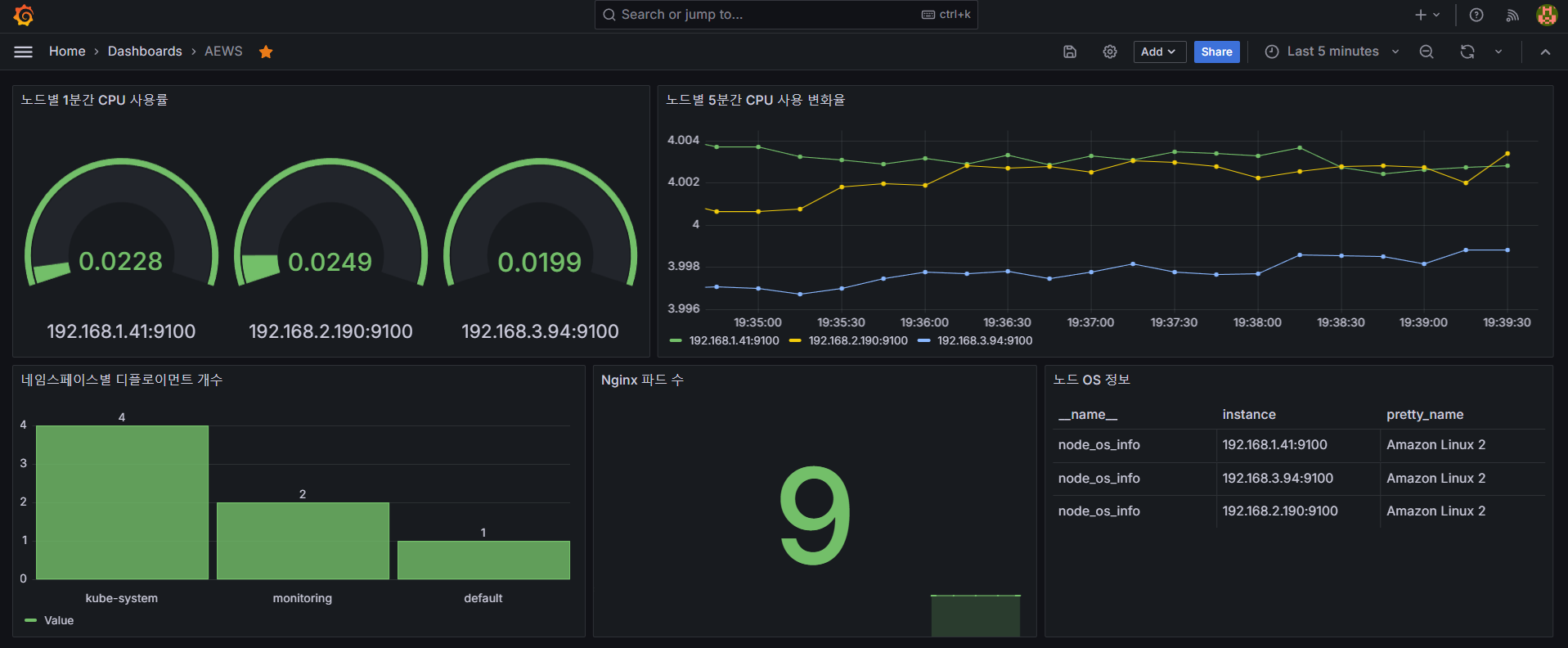
- Time series : Worker Node별 5분 간 CPU 사용 변화율
- Bar chart : 네임스페이스별 디플로이먼트 개수

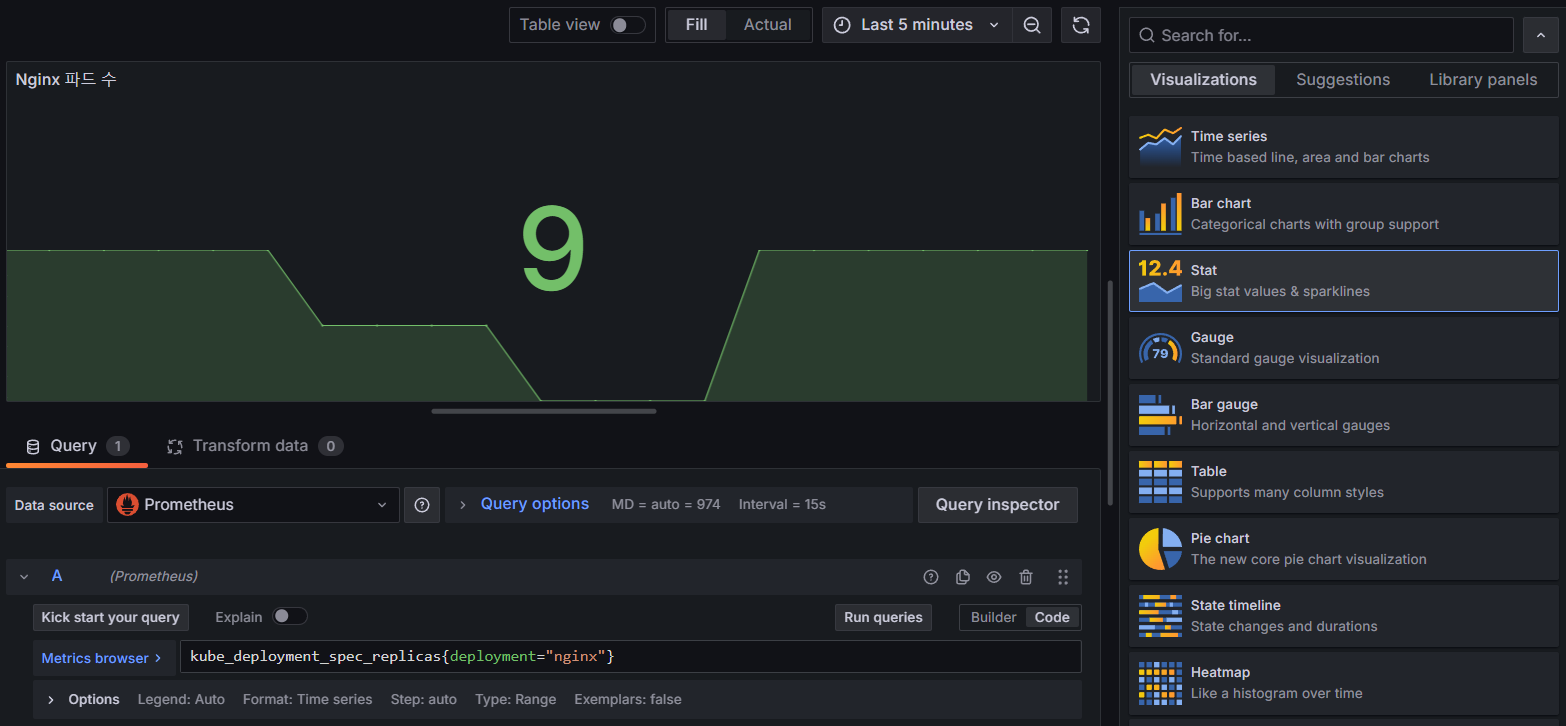
- Stat : Nginx 파드 수
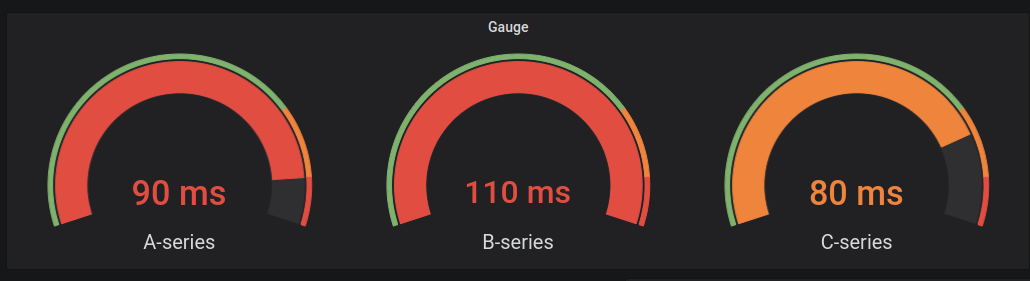
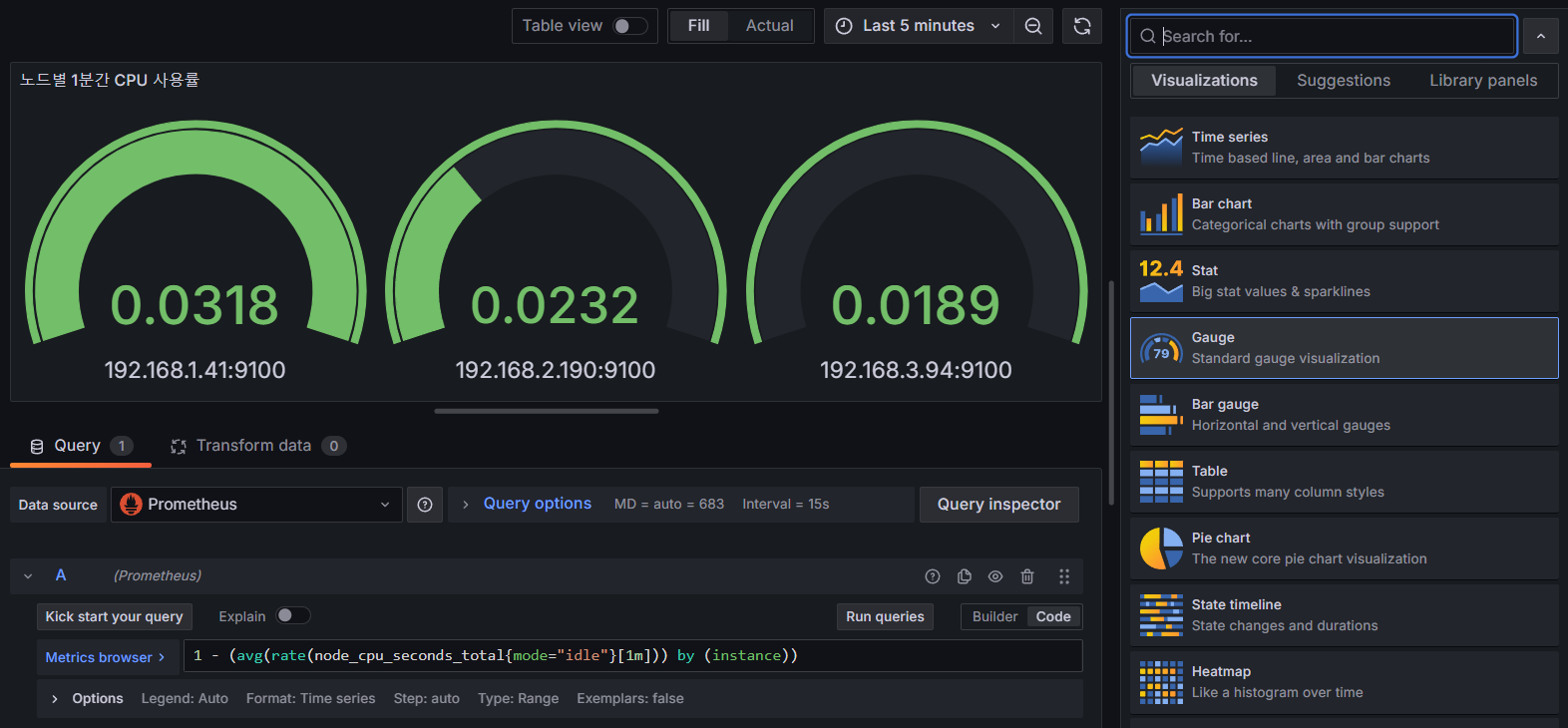
- Gauge : Woreker Node별 1분 간 CPU 사용률
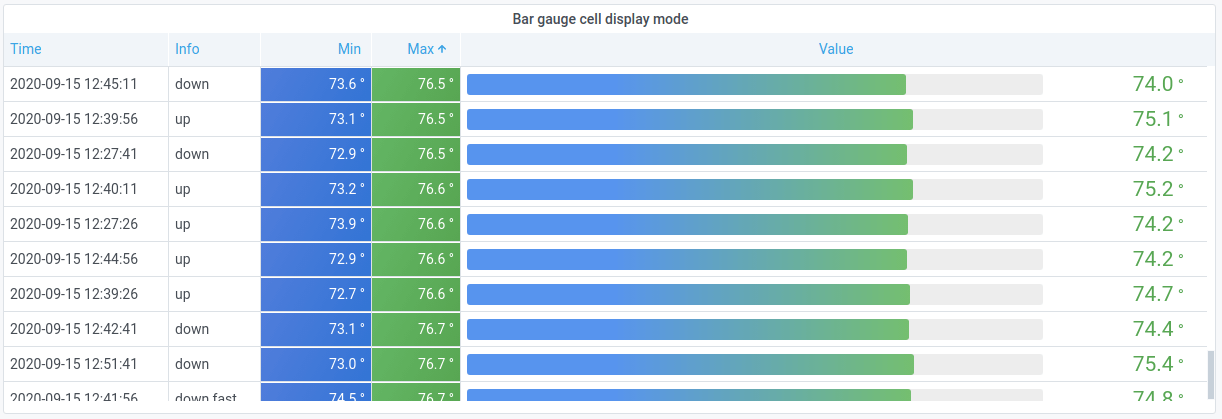
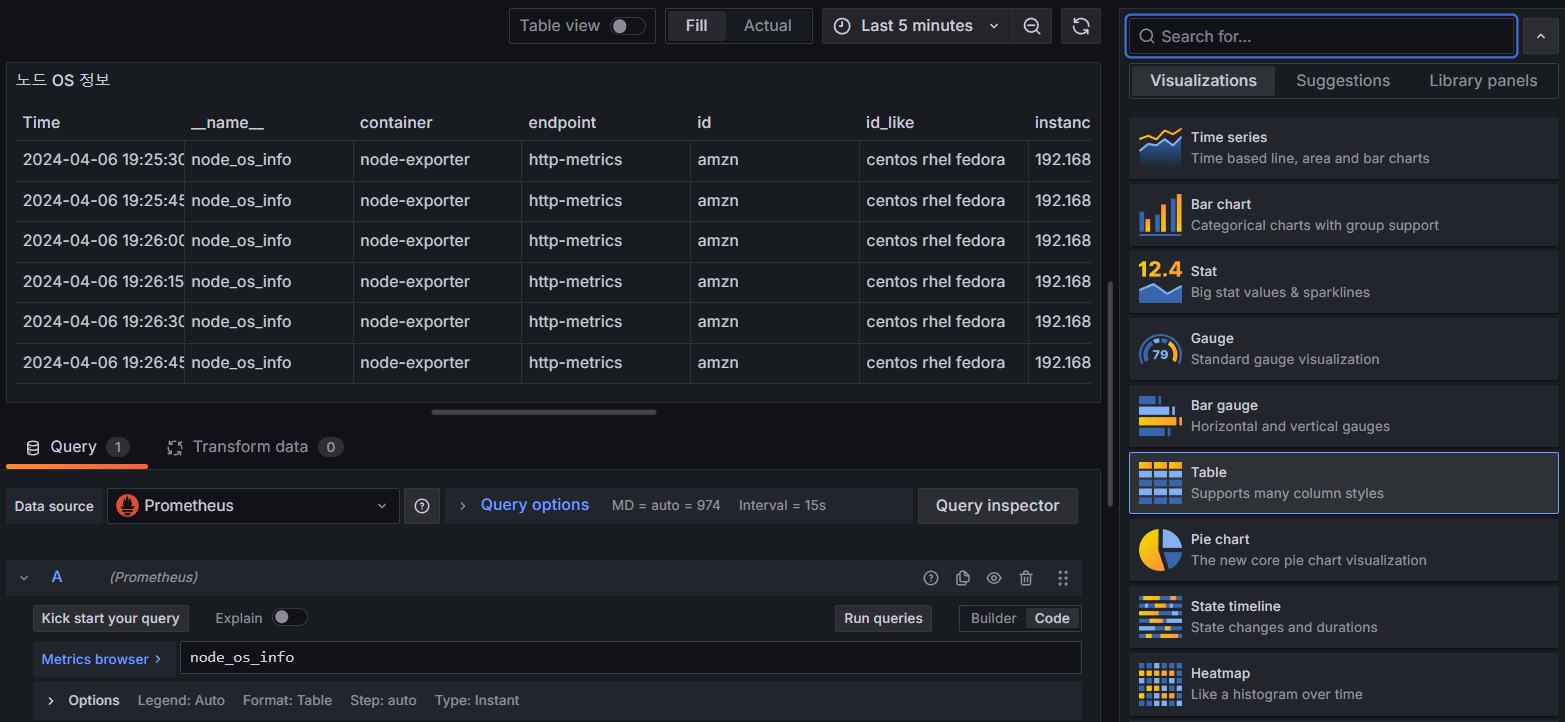
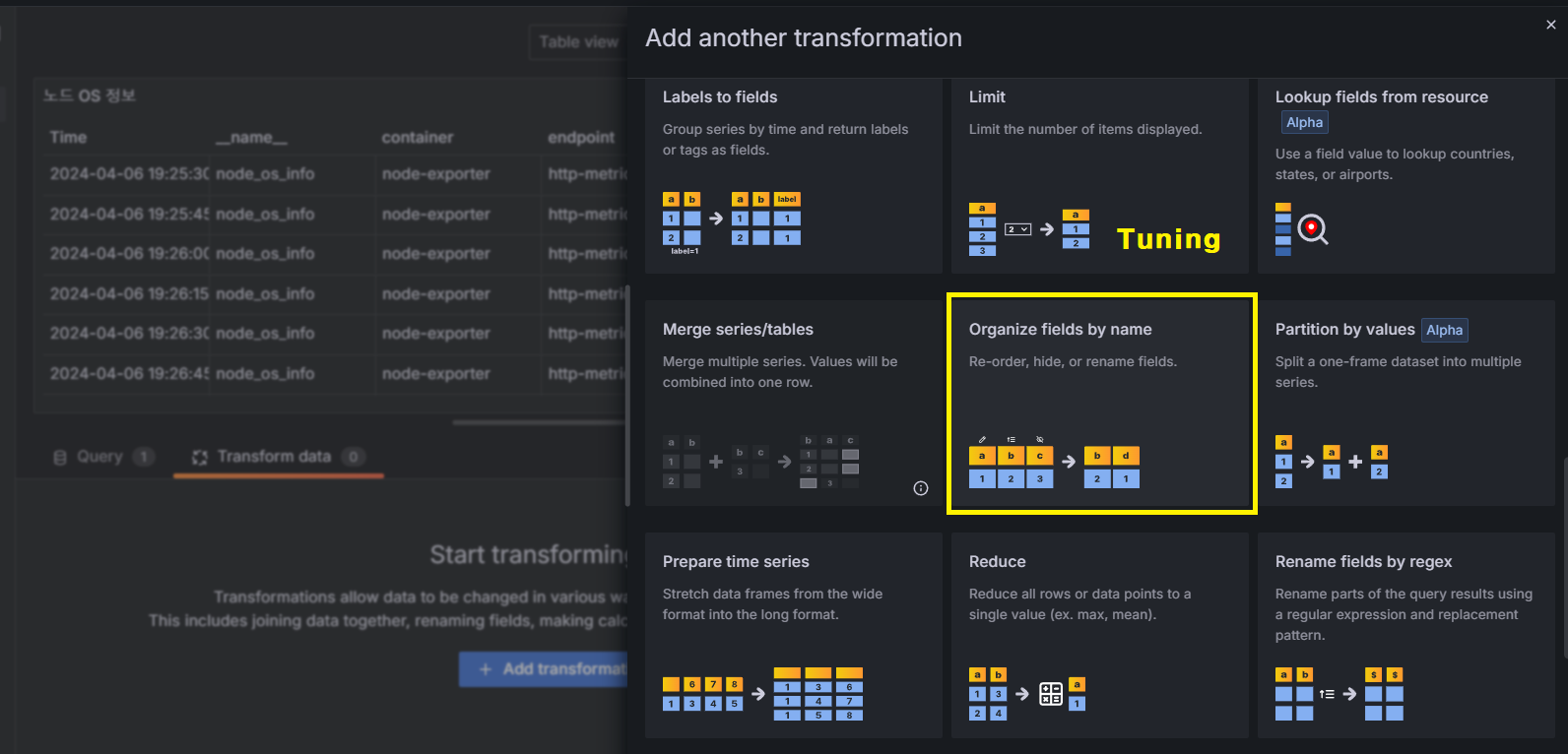
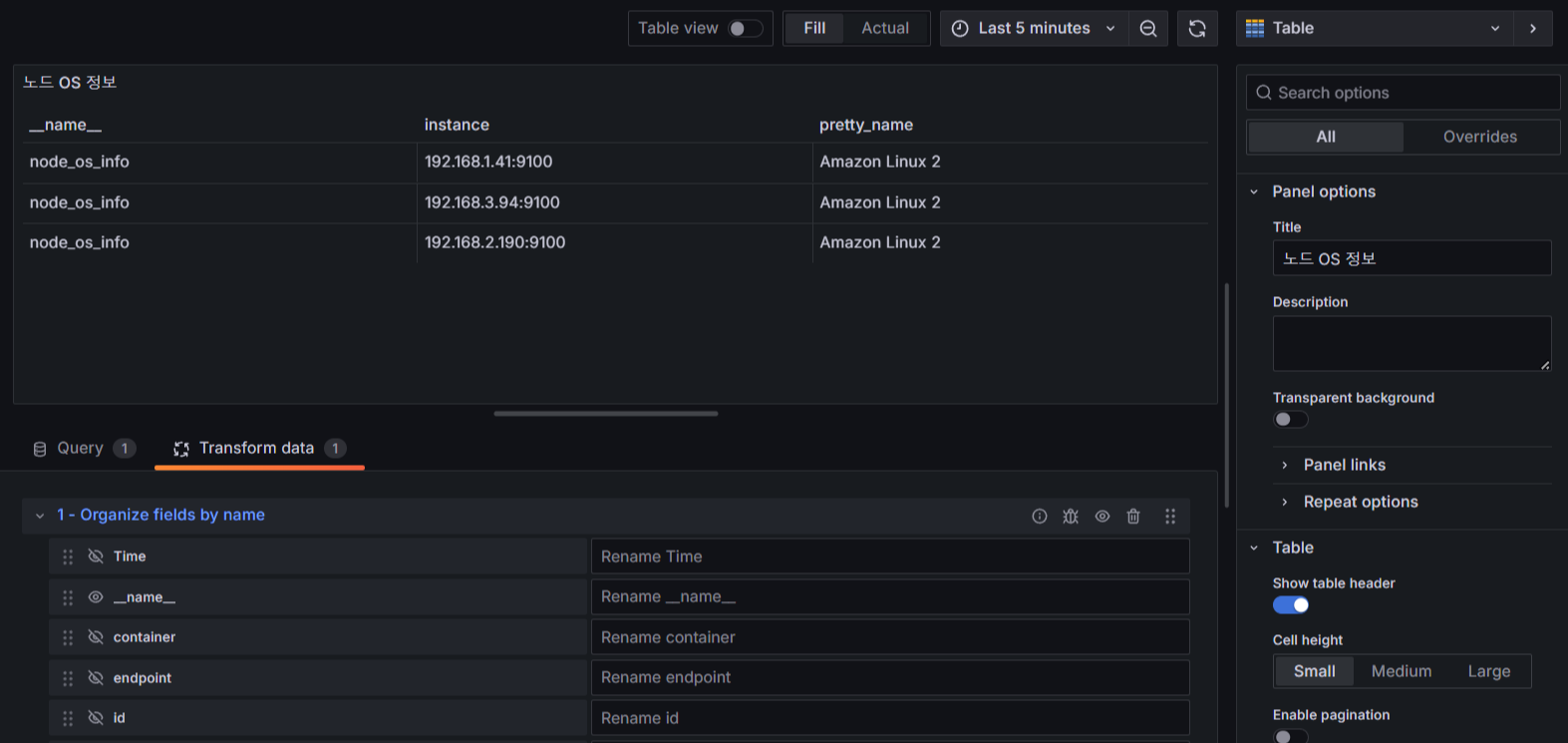
- Table : Worker Node OS 정보
- 최종 대시보드 구성 화면
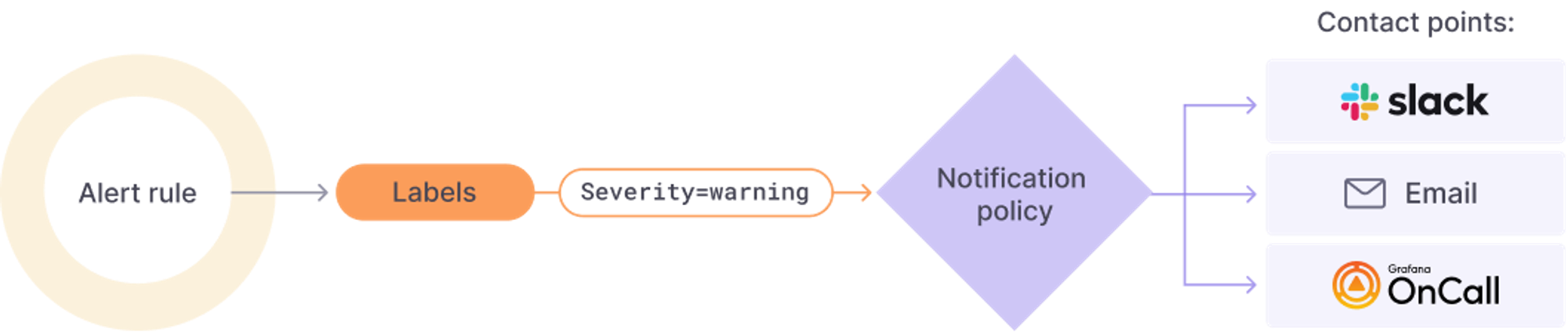
Alert
Prometheus 뿐만 아니라 Grafana에서도 Alert 기능을 지원하고 있습니다.
Slack, Email 등과 연동하여 정책을 설정하고 알람을 받아볼 수 있습니다.
[출처]
1) CloudNet@, AEWS 실습 스터디
2) https://prometheus.io/docs/introduction/overview/
Overview | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
3) https://docs.aws.amazon.com/eks/latest/userguide/prometheus.html
Prometheus metrics - Amazon EKS
If you get the error Error: failed to download "stable/prometheus" (hint: running `helm repo update` may help) when executing this command, run helm repo update prometheus-community, and then try running the Step 2 command again. If you get the error Error
docs.aws.amazon.com
4) https://cloudnativenow.com/topics/cloudnativeplatforms/cluster-monitoring-with-prometheus-operator/
Cluster Monitoring With Prometheus Operator
This article focuses on role of Prometheus Operator, how it works and how service monitoring works to discover targets and scrape metrics.
cloudnativenow.com
5) https://www.opsramp.com/guides/prometheus-monitoring/prometheus-node-exporter/
Guide To The Prometheus Node Exporter : OpsRamp
Learn about the Prometheus Node Exporter’s default and optional collectors along with instructions on how to install and configure it.
www.opsramp.com
6) https://prometheus.io/docs/prometheus/latest/querying/basics/
Querying basics | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
7) https://prometheus.io/docs/prometheus/latest/querying/operators/
Operators | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
8) https://prometheus.io/docs/prometheus/latest/querying/operators/#binary-operators
Operators | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
9) https://prometheus.io/docs/prometheus/latest/querying/operators/#aggregation-operators
Operators | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
10) https://grafana.com/docs/grafana/latest/introduction/
About Grafana | Grafana documentation
Thank you! Your message has been received!
grafana.com
11) https://grafana.com/grafana/dashboards/?pg=docs-grafana-latest-dashboards
Dashboards | Grafana Labs
Thank you! Your message has been received!
grafana.com
12) https://grafana.com/docs/grafana/latest/panels-visualizations/visualizations/
Visualizations | Grafana documentation
Thank you! Your message has been received!
grafana.com
'AWS > EKS' 카테고리의 다른 글
| [AEWS2] 5-2. Karpenter (1) | 2024.04.07 |
|---|---|
| [AEWS2] 5-1. EKS AutoScaling (1) | 2024.04.07 |
| [AEWS2] 4-1. EKS Observability (0) | 2024.03.31 |
| [AEWS2] 3-1. EKS Storage & Nodegroup (1) | 2024.03.24 |
| [AEWS2] 2-5. Network Policies with VPC CNI (0) | 2024.03.17 |



