



✍ Posted by Immersive Builder Seong
HPA(Horizontal Pod Autoscaler)
파드의 수를 스케일 아웃하여 서비스 요청을 여러 파드로 분산시키는 방법입니다.
쿠버네티스의 HPA 컨트롤러는 주기적으로 메트릭스토어로부터 파드의 메트릭을 취득하며,
취득한 메트릭을 기반으로 필요한 파드 수를 계산하고, 레플리카셋 및 디플로이먼트 파드 수를 변경합니다.
HPA가 동작하는 모습을 kube-ops-view와 그라파나를 통해 모니터링해봅시다.
반복 연산을 수행하는 php-apache 서버를 배포하여 접속합니다.
# php-apache server 배포
$ curl -s -O https://raw.githubusercontent.com/kubernetes/website/main/content/en/examples/application/php-apache.yaml
$ kubectl apply -f php-apache.yaml
# 배포 확인
$ kubectl exec -it deploy/php-apache -- cat /var/www/html/index.php
/* 반복 연산을 수행하여 CPU 부하 발생
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "OK!";
?>
# php-apache server 접속
$ PODIP=$(kubectl get pod -l run=php-apache -o jsonpath={.items[0].status.podIP})
$ curl -s $PODIP; echo
OK!
# 모니터링
$ watch -d 'kubectl get hpa,pod;echo;kubectl top pod;echo;kubectl top node'
Every 2.0s: kubectl get hpa,pod;echo;kubectl top pod;echo;kubectl top node Sun Apr 7 00:54:35 2024
NAME READY STATUS RESTARTS AGE
pod/php-apache-598b474864-8ltgk 1/1 Running 0 7m12s
NAME CPU(cores) MEMORY(bytes)
php-apache-598b474864-8ltgk 1m 9Mi
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
ip-192-168-1-83.ap-northeast-2.compute.internal 53m 2% 764Mi 23%
ip-192-168-2-114.ap-northeast-2.compute.internal 90m 4% 979Mi 29%
ip-192-168-3-63.ap-northeast-2.compute.internal 61m 3% 852Mi 25%
$ kubectl exec -it deploy/php-apache -- top
top - 15:55:00 up 2:03, 0 users, load average: 0.18, 0.14, 0.12
Tasks: 7 total, 1 running, 6 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.7 us, 0.7 sy, 0.0 ni, 98.2 id, 0.0 wa, 0.0 hi, 0.2 si, 0.3 st
KiB Mem: 3943352 total, 3518456 used, 424896 free, 2704 buffers
KiB Swap: 0 total, 0 used, 0 free. 2773560 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 166268 19316 14048 S 0.0 0.5 0:00.08 apache2
8 www-data 20 0 166348 10228 4892 S 0.0 0.3 0:00.10 apache2
9 www-data 20 0 166292 7148 1868 S 0.0 0.2 0:00.00 apache2
10 www-data 20 0 166292 7148 1868 S 0.0 0.2 0:00.00 apache2
11 www-data 20 0 166292 7148 1868 S 0.0 0.2 0:00.00 apache2
12 www-data 20 0 166292 7148 1868 S 0.0 0.2 0:00.00 apache2
19 root 20 0 21920 2400 2072 R 0.0 0.1 0:00.03 top
한 번 접속하였을 때에는 아무런 변화가 없습니다.
다시 HPA 정책을 생성하여 부하를 발생시킨 후 테스트합니다.
HPA 정책은 CPU 사용률이 50% 이상일 때 파드의 수를 최소 1개(min)부터 최대 10개(max)까지 증설합니다.
# HPA 정책 생성
$ kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
horizontalpodautoscaler.autoscaling/php-apache autoscaled
$ kubectl describe hpa
Name: php-apache
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Sun, 07 Apr 2024 01:06:52 +0900
Reference: Deployment/php-apache
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (1m) / 50%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events: <none>
# HPA 정책 확인
$ kubectl get hpa php-apache -o yaml | kubectl neat
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
# php-apache server 반복 접속 1
$ while true;do curl -s $PODIP; sleep 0.5; done
OK!OK!OK!OK!OK!OK!
# 모니터링 1
$ watch -d 'kubectl get hpa,pod;echo;kubectl top pod;echo;kubectl top node'
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/php-apache Deployment/php-apache 69%/50% 1 10 2 4m38s
NAME READY STATUS RESTARTS AGE
pod/php-apache-598b474864-8ltgk 1/1 Running 0 24m
pod/php-apache-598b474864-v6cpw 1/1 Running 0 23s
NAME CPU(cores) MEMORY(bytes)
php-apache-598b474864-8ltgk 139m 12Mi
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
ip-192-168-1-83.ap-northeast-2.compute.internal 197m 10% 770Mi 23%
ip-192-168-2-114.ap-northeast-2.compute.internal 633m 32% 984Mi 29%
ip-192-168-3-63.ap-northeast-2.compute.internal 64m 3% 861Mi 26%
$ kubectl exec -it deploy/php-apache -- top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
12 www-data 20 0 166348 10800 5436 S 14.6 0.3 0:02.24 apache2
1 root 20 0 166268 19316 14048 S 0.0 0.5 0:00.11 apache2
8 www-data 20 0 166348 10800 5436 S 0.0 0.3 0:02.29 apache2
9 www-data 20 0 166348 10800 5436 S 0.0 0.3 0:02.25 apache2
10 www-data 20 0 166348 10800 5436 S 0.0 0.3 0:02.22 apache2
11 www-data 20 0 166348 10800 5436 S 0.0 0.3 0:02.17 apache2
19 root 20 0 21920 2400 2072 R 0.0 0.1 0:00.20 top
25 www-data 20 0 166348 10800 5436 S 0.0 0.3 0:02.04 apache2
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
php-apache-598b474864-8ltgk 1/1 Running 0 25m
php-apache-598b474864-v6cpw 1/1 Running 0 109s
# php-apache server 반복 접속 2
$ kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!
# 모니터링 2
$ watch -d 'kubectl get hpa,pod;echo;kubectl top pod;echo;kubectl top node'
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/php-apache Deployment/php-apache 111%/50% 1 10 4 9m26s
NAME READY STATUS RESTARTS AGE
pod/load-generator 1/1 Running 0 52s
pod/php-apache-598b474864-5hmtf 1/1 Running 0 10s
pod/php-apache-598b474864-8ltgk 1/1 Running 0 28m
pod/php-apache-598b474864-cqczt 1/1 Running 0 25s
pod/php-apache-598b474864-v6cpw 1/1 Running 0 5m11s
pod/php-apache-598b474864-wtvxk 1/1 Running 0 25s
NAME CPU(cores) MEMORY(bytes)
load-generator 9m 0Mi
php-apache-598b474864-8ltgk 177m 12Mi
php-apache-598b474864-cqczt 186m 11Mi
php-apache-598b474864-v6cpw 209m 11Mi
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
ip-192-168-1-83.ap-northeast-2.compute.internal 381m 19% 792Mi 23%
ip-192-168-2-114.ap-northeast-2.compute.internal 356m 18% 1071Mi 32%
ip-192-168-3-63.ap-northeast-2.compute.internal 739m 38% 944Mi 28%
$ kubectl exec -it deploy/php-apache -- top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8 www-data 20 0 166348 10808 5436 S 13.9 0.3 0:07.36 apache2
11 www-data 20 0 166348 10808 5436 S 13.9 0.3 0:07.28 apache2
1 root 20 0 166268 19316 14048 S 0.0 0.5 0:00.12 apache2
9 www-data 20 0 166348 10808 5436 S 0.0 0.3 0:07.28 apache2
10 www-data 20 0 166348 10808 5436 S 0.0 0.3 0:07.19 apache2
12 www-data 20 0 166348 10808 5436 S 0.0 0.3 0:07.28 apache2
19 root 20 0 21920 2400 2072 R 0.0 0.1 0:00.25 top
25 www-data 20 0 166348 10808 5436 S 0.0 0.3 0:07.06 apache2
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
load-generator 1/1 Running 0 86s
php-apache-598b474864-5hmtf 1/1 Running 0 44s
php-apache-598b474864-8ltgk 1/1 Running 0 29m
php-apache-598b474864-cqczt 1/1 Running 0 59s
php-apache-598b474864-v6cpw 1/1 Running 0 5m45s
php-apache-598b474864-wtvxk 1/1 Running 0 59s
php-apache-598b474864-zp27z 1/1 Running 0 29s
부하를 발생시킴에 따라 파드가 하나씩 늘어나 현재 6개가 생성된 모습입니다.
Desired Replicas는 정책에 기반하여 생성되어야 할 기대 파드 수이며, Current Replicas는 실제 생성된 파드 수입니다.
하기 그래프에서 Desired Replicas가 먼저 증가하고 Current Replicas가 따라서 증가하는 모습을 확인할 수 있습니다.
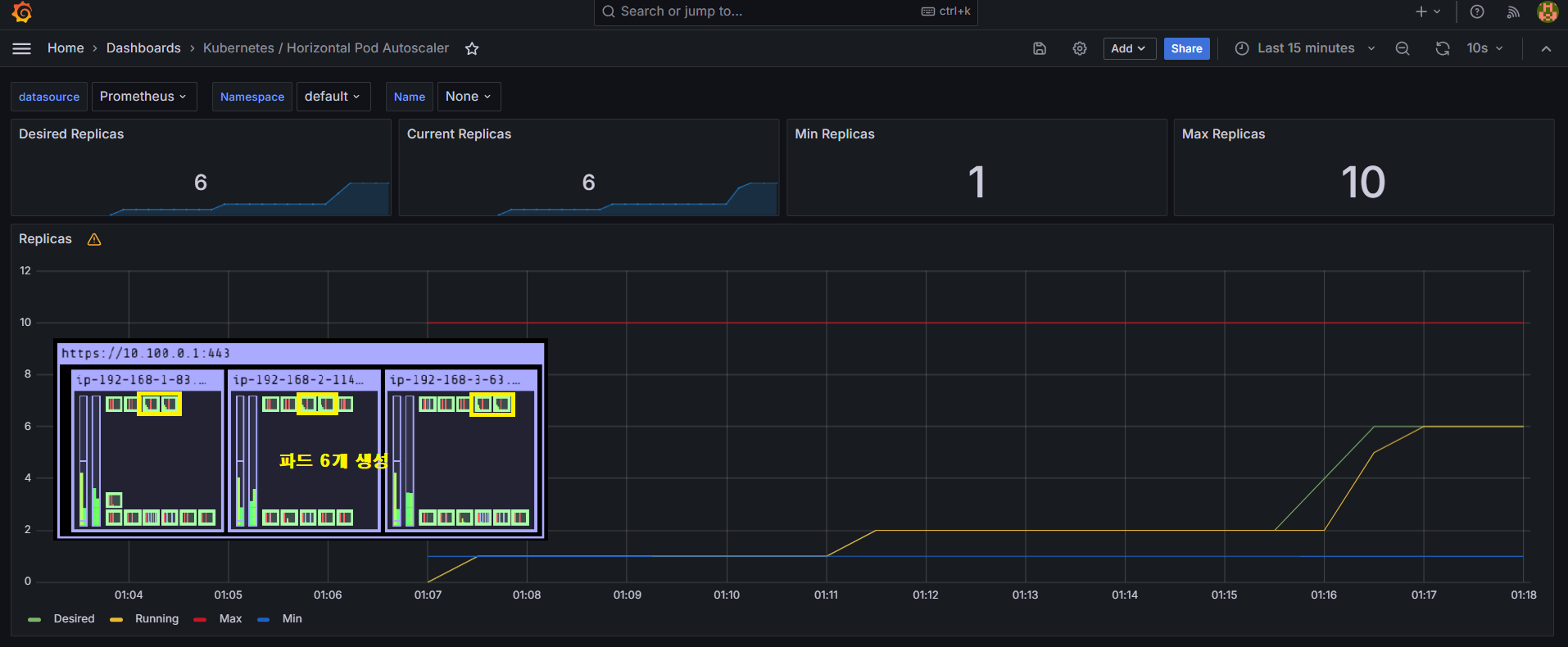
일정 시간이 지나면 파드 수량이 유지됩니다.
저의 경우에는 파드 6개에서 더 이상 생성되지 않는 모습입니다.
그 이유는 파드가 부하를 분산 처리하여 CPU 사용률이 50% 이하로 내려가면서 안정적인 운영 상태로 접어들었기 때문입니다.
그리고 부하를 종료하면 파드 수는 다시 최소 수량 한 개로 줄어들게 됩니다.

KEDA(Kubernetes based Event Driven Autoscaler)
기존의 HPA는 오로지 리소스 메트릭(CPU, MEM)을 기반으로 스케일 여부를 결정합니다.
반면, KEDA 컨트롤러는 특정 이벤트를 기반으로 스케일 여부를 결정할 수 있습니다.
예를 들어 AWS SQS Queue, CloudWatch, DynamoDB, Apache Kafka 등 어플리케이션에서 발생하는 메트릭을 기반으로 스케일 인아웃할 수 있으므로 활용 범위가 다양한 것이 장점입니다.

우선 KEDA를 설치하고 구성해봅시다.
KEDA는 별도의 메트릭 서버(keda-operator-metrics-apiserver)를 운용합니다.
# KEDA 설치
$ cat <<EOT > keda-values.yaml
metricsServer:
useHostNetwork: true
prometheus:
metricServer:
enabled: true
port: 9022
portName: metrics
path: /metrics
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
operator:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
webhooks:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus webhooks
enabled: true
EOT
$ kubectl create namespace keda
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/keda --version 2.13.0 --namespace keda -f keda-values.yaml
NAME: keda
LAST DEPLOYED: Sun Apr 7 02:07:49 2024
NAMESPACE: keda
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
:::^. .::::^: ::::::::::::::: .:::::::::. .^.
7???~ .^7????~. 7??????????????. :?????????77!^. .7?7.
7???~ ^7???7~. ~!!!!!!!!!!!!!!. :????!!!!7????7~. .7???7.
7???~^7????~. :????: :~7???7. :7?????7.
7???7????!. ::::::::::::. :????: .7???! :7??77???7.
7????????7: 7???????????~ :????: :????: :???7?5????7.
7????!~????^ !77777777777^ :????: :????: ^???7?#P7????7.
7???~ ^????~ :????: :7???! ^???7J#@J7?????7.
7???~ :7???!. :????: .:~7???!. ~???7Y&@#7777????7.
7???~ .7???7: !!!!!!!!!!!!!!! :????7!!77????7^ ~??775@@@GJJYJ?????7.
7???~ .!????^ 7?????????????7. :?????????7!~: !????G@@@@@@@@5??????7:
::::. ::::: ::::::::::::::: .::::::::.. .::::JGGGB@@@&7:::::::::
# KEDA 설치 확인
$ kubectl get all -n keda
NAME READY STATUS RESTARTS AGE
pod/keda-admission-webhooks-5bffd88dcf-jp929 1/1 Running 0 52s
pod/keda-operator-856b546d-pwl74 1/1 Running 1 (41s ago) 52s
pod/keda-operator-metrics-apiserver-5666945c65-lcfh8 1/1 Running 0 52s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/keda-admission-webhooks ClusterIP 10.100.147.209 <none> 443/TCP,8080/TCP 52s
service/keda-operator ClusterIP 10.100.49.72 <none> 9666/TCP,8080/TCP 52s
service/keda-operator-metrics-apiserver ClusterIP 10.100.141.216 <none> 443/TCP,9022/TCP 52s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/keda-admission-webhooks 1/1 1 1 52s
deployment.apps/keda-operator 1/1 1 1 52s
deployment.apps/keda-operator-metrics-apiserver 1/1 1 1 52s
NAME DESIRED CURRENT READY AGE
replicaset.apps/keda-admission-webhooks-5bffd88dcf 1 1 1 52s
replicaset.apps/keda-operator-856b546d 1 1 1 52s
replicaset.apps/keda-operator-metrics-apiserver-5666945c65 1 1 1 52s
$ kubectl get validatingwebhookconfigurations keda-admission
NAME WEBHOOKS AGE
keda-admission 3 73s
$ kubectl get crd | grep keda
cloudeventsources.eventing.keda.sh 2024-04-06T17:07:51Z
clustertriggerauthentications.keda.sh 2024-04-06T17:07:51Z
scaledjobs.keda.sh 2024-04-06T17:07:51Z
scaledobjects.keda.sh 2024-04-06T17:07:51Z
triggerauthentications.keda.sh 2024-04-06T17:07:51Z
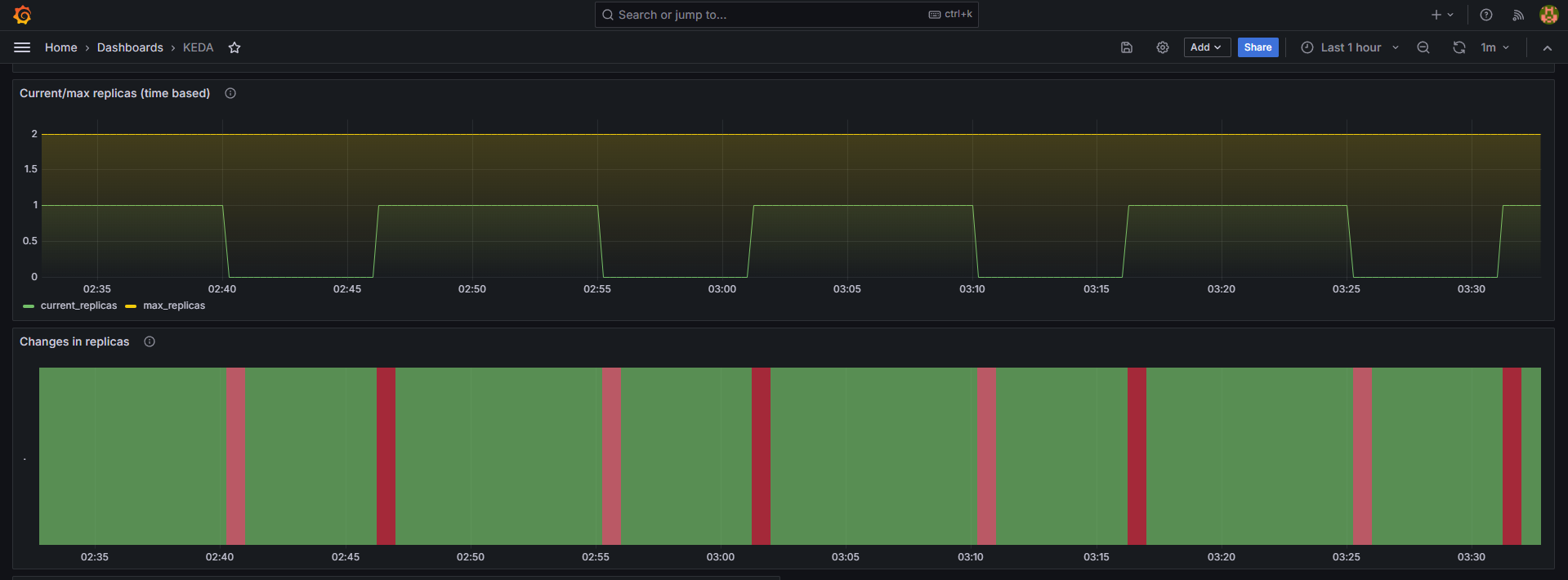
Cron 이벤트를 기반으로 KEDA의 동작을 확인해보겠습니다.
"매시 00, 15, 30, 45분" 마다 파드의 수량을 하나 늘리고 다시 "매시 05, 20, 35, 50분" 마다 파드의 수량을 하나 줄이도록 Cron 정책을 설정할 것입니다.
예상 결과는 파드의 수량이 증가한 시점으로부터 5분이 지난 후 감소하는 그래프를 반복하는 것입니다.
# keda 네임스페이스에 디플로이먼트 생성
$ kubectl apply -f php-apache.yaml -n keda
$ kubectl get pod -n keda
# ScaledObject 정책 생성: Cron
$ cat <<EOT > keda-cron.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: php-apache-cron-scaled
spec:
minReplicaCount: 0
maxReplicaCount: 2
pollingInterval: 30
cooldownPeriod: 300
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
triggers:
- type: cron
metadata:
timezone: Asia/Seoul
start: 00,15,30,45 * * * *
end: 05,20,35,50 * * * *
desiredReplicas: "1"
EOT
$ kubectl apply -f keda-cron.yaml -n keda
scaledobject.keda.sh/php-apache-cron-scaled created
# 정책 배포 확인
$ kubectl get ScaledObject,hpa,pod -n keda
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK PAUSED AGE
scaledobject.keda.sh/php-apache-cron-scaled apps/v1.Deployment php-apache 0 2 cron True True Unknown Unknown 45s
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-php-apache-cron-scaled Deployment/php-apache <unknown>/1 (avg) 1 2 0 44s
NAME READY STATUS RESTARTS AGE
pod/keda-admission-webhooks-5bffd88dcf-jp929 1/1 Running 0 11m
pod/keda-operator-856b546d-pwl74 1/1 Running 1 (11m ago) 11m
pod/keda-operator-metrics-apiserver-5666945c65-lcfh8 1/1 Running 0 11m
pod/php-apache-598b474864-5hqct 1/1 Running 0 95s
$ kubectl get hpa -o jsonpath={.items[0].spec} -n keda
{"maxReplicas":2,"metrics":[{"external":{"metric":{"name":"s0-cron-Asia-Seoul-00,15,30,45xxxx-05,20,35,50xxxx","selector":{"matchLabels":{"scaledobject.keda.sh/name":"php-apache-cron-scaled"}}},"target":{"averageValue":"1","type":"AverageValue"}},"type":"External"}],"minReplicas":1,"scaleTargetRef":{"apiVersion":"apps/v1","kind":"Deployment","name":"php-apache"}}
# 모니터링
$ watch -d 'kubectl get ScaledObject,hpa,pod -n keda'
$ kubectl get ScaledObject -w
Grafana 대시보드에서 파드의 수량이 주기적으로 반복되는 그래프를 확인할 수 있습니다.
VPA(Vertical Pod Autoscaler)
파드의 성능을 스케일 업하여 서비스 요청을 처리하는 방법입니다.
파드에 할당하는 리소스(CPU, MEM)는 request(하한선)와 limit(상한선) 두 개의 파라미터에 의해 정해집니다.
쿠버네티스의 VPA 컨트롤러는 리소스 사용률에 따라 request와 limit 파라미터 값을 자동으로 조정하여 파드를 수직 스케일링합니다.

VPA를 배포하고 구성합니다.
사전에 Openssl v1.1.1 이상 버전이 설치되어 있어야 합니다.
# Code Download
$ git clone https://github.com/kubernetes/autoscaler.git
$ cd ~/autoscaler/vertical-pod-autoscaler/
$ tree hack
hack
├── boilerplate.go.txt
├── convert-alpha-objects.sh
├── deploy-for-e2e-locally.sh
├── deploy-for-e2e.sh
├── e2e
│ ├── Dockerfile.externalmetrics-writer
│ ├── k8s-metrics-server.yaml
│ ├── kind-with-registry.sh
│ ├── metrics-pump.yaml
│ ├── prometheus-adapter.yaml
│ ├── prometheus.yaml
│ ├── recommender-externalmetrics-deployment.yaml
│ └── vpa-rbac.diff
├── emit-metrics.py
├── generate-crd-yaml.sh
├── local-cluster.md
├── run-e2e-locally.sh
├── run-e2e.sh
├── run-e2e-tests.sh
├── update-codegen.sh
├── update-kubernetes-deps-in-e2e.sh
├── update-kubernetes-deps.sh
├── verify-codegen.sh
├── vpa-apply-upgrade.sh
├── vpa-down.sh
├── vpa-process-yaml.sh
├── vpa-process-yamls.sh
├── vpa-up.sh
└── warn-obsolete-vpa-objects.sh
# openssl 1.1.1 이상 버전 확인
$ yum install openssl11 -y
Installed:
openssl11.x86_64 1:1.1.1g-12.amzn2.0.20
$ openssl11 version
OpenSSL 1.1.1g FIPS 21 Apr 2020
# 스크립트파일 내 openssl11 수정
$ sed -i 's/openssl/openssl11/g' ~/autoscaler/vertical-pod-autoscaler/pkg/admission-controller/gencerts.sh
# VPA 배포
$ ./hack/vpa-up.sh
customresourcedefinition.apiextensions.k8s.io/verticalpodautoscalercheckpoints.autoscaling.k8s.io created
customresourcedefinition.apiextensions.k8s.io/verticalpodautoscalers.autoscaling.k8s.io created
clusterrole.rbac.authorization.k8s.io/system:metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:vpa-actor created
clusterrole.rbac.authorization.k8s.io/system:vpa-status-actor created
clusterrole.rbac.authorization.k8s.io/system:vpa-checkpoint-actor created
clusterrole.rbac.authorization.k8s.io/system:evictioner created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/system:vpa-actor created
clusterrolebinding.rbac.authorization.k8s.io/system:vpa-status-actor created
clusterrolebinding.rbac.authorization.k8s.io/system:vpa-checkpoint-actor created
clusterrole.rbac.authorization.k8s.io/system:vpa-target-reader created
clusterrolebinding.rbac.authorization.k8s.io/system:vpa-target-reader-binding created
clusterrolebinding.rbac.authorization.k8s.io/system:vpa-evictioner-binding created
serviceaccount/vpa-admission-controller created
serviceaccount/vpa-recommender created
serviceaccount/vpa-updater created
clusterrole.rbac.authorization.k8s.io/system:vpa-admission-controller created
clusterrolebinding.rbac.authorization.k8s.io/system:vpa-admission-controller created
clusterrole.rbac.authorization.k8s.io/system:vpa-status-reader created
clusterrolebinding.rbac.authorization.k8s.io/system:vpa-status-reader-binding created
deployment.apps/vpa-updater created
deployment.apps/vpa-recommender created
Generating certs for the VPA Admission Controller in /tmp/vpa-certs.
Generating RSA private key, 2048 bit long modulus (2 primes)
.............................................................+++++
..+++++
e is 65537 (0x010001)
Can't load /root/.rnd into RNG'
140622337369920:error:2406F079:random number generator:RAND_load_file:Cannot open file:crypto/rand/randfile.c:98:Filename=/root/.rnd
Generating RSA private key, 2048 bit long modulus (2 primes)
.+++++
.....................................................................+++++
e is 65537 (0x010001)
Signature ok
subject=CN = vpa-webhook.kube-system.svc
Getting CA Private Key
Uploading certs to the cluster.
secret/vpa-tls-certs created
Deleting /tmp/vpa-certs.
deployment.apps/vpa-admission-controller created
service/vpa-webhook created
$ watch -d kubectl get pod -n kube-system
vpa-admission-controller-bd8675cb-wdsgq 1/1 Running 0 2m1s
vpa-recommender-74d566f9b9-fc5sl 1/1 Running 0 2m4s
vpa-updater-65d95b7c68-ptbbl 1/1 Running 0 2m7s
$ kubectl get crd | grep autoscaling
verticalpodautoscalercheckpoints.autoscaling.k8s.io 2024-04-06T18:02:06Z
verticalpodautoscalers.autoscaling.k8s.io 2024-04-06T18:02:06Z
$ kubectl get mutatingwebhookconfigurations vpa-webhook-config
NAME WEBHOOKS AGE
vpa-webhook-config 1 29s
$ kubectl get mutatingwebhookconfigurations vpa-webhook-config -o json | jq
{
"apiVersion": "admissionregistration.k8s.io/v1",
"kind": "MutatingWebhookConfiguration",
"metadata": {
"creationTimestamp": "2024-04-06T18:02:34Z",
"generation": 1,
"name": "vpa-webhook-config",
"resourceVersion": "73811",
"uid": "6a406277-fc45-4ecd-960c-98bd4f57792d"
},
"webhooks": [
{
"admissionReviewVersions": [
"v1"
],
"clientConfig": {
"caBundle": "LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURMVENDQWhXZ0F3SUJBZ0lVY3h3cTBaQS9EWjVyKzBwV1FQTVlDYWpBaEdRd0RRWUpLb1pJaHZjTkFRRUwKQlFBd0dURVhNQlVHQTFVRUF3d09kbkJoWDNkbFltaHZiMnRmWTJFd0lCY05NalF3TkRBMk1UZ3dNakUyV2hnUApNakk1T0RBeE1qQXhPREF5TVRaYU1Ca3hGekFWQmdOVkJBTU1Eblp3WVY5M1pXSm9iMjlyWDJOaE1JSUJJakFOCkJna3Foa2lHOXcwQkFRRUZBQU9DQVE4QU1JSUJDZ0tDQVFFQTFMU2ptNHpRN0E2MzdPSWNxY2M4dWZucDlvcnUKc2V2UkxpNjdObW54ajc1Q2xWMUgyQTB4NTNzRWNYeFg2S3NUbzB0SmZValJyV0hVODVIV0c5N1R4Q05tTElRTgpoSDE4WUFHOEYrakk0Vkw0eTdUQlBmcXRVR0JIZTJhUmY0eVJsWEt5M3F1WVVTaWdvVDE0ZUdtQzRCeVBiV0IzCmNvV0tQTU82VmF1NWZ6eU9XQTlsZHVjcFJvbFdOemljdkM3N3dVR21TalRjZlRyRER6QzlEZDc1akRlN1IvSm4Kangvc3lJK2xPQlAwVGxOSjJmMHptY3krUkM4ZEFxVDE0TXROa3EvK1RUY0JFNnlzUDRkT0lQMFpGdWppcGlrQQo4bldVdlZvMnJ2UWs3aHVHSEtTamZTb3pVbjQ0dGdGY1ZXdFhjaUlvM0tLMGxNbzNxdzBtbkhEVnh3SURBUUFCCm8yc3dhVEFkQmdOVkhRNEVGZ1FVUGRRaG9rTHJpNitFYzhCTG92Z2J6WmFPTFowd0h3WURWUjBqQkJnd0ZvQVUKUGRRaG9rTHJpNitFYzhCTG92Z2J6WmFPTFowd0RBWURWUjBUQkFVd0F3RUIvekFaQmdOVkhSRUVFakFRZ2c1MgpjR0ZmZDJWaWFHOXZhMTlqWVRBTkJna3Foa2lHOXcwQkFRc0ZBQU9DQVFFQVFwakphWVJ1TnNLOGQvT25WUWtTClpZMFIxUkcwNW9qMWpJWVdrVXhjWElCNStnSCtZR0RRSVZoNWZpRm9KeTFqOHVURm5uWDArY1hxdERLbnhaUVQKQ3hrbm9obzVnUDJleVhqenc2dGR5TGlTcFUvS1ZjV3VOSUgrYXpzV1hkQ3dmaFN3RW54KzY3cCsxL0tFSCtWTwo4MkhBMk9VTzdRS2ZDNXprK1hnQ1gyR0JxR3dodThSNm9IbjErdWFrQ0k1T09FcDhYTVovelBzV2tCYVVVVU1pCll6eFBhYUZWZHBuL1dQNGhJZk1NdlR3bzBDVk8raFBqSjF0cERLdmExVGtOUTVqbStQVEZZK1ppb2h3QWhFa2sKQlRIbDRJdVVSTUVPNmNzdkEwVmRVSjM1S2U3TUEzdlZxYmVWcmw0MlBpRzRQbEdFODVSMXRHRjZyYUFOaTdESQppQT09Ci0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0K",
"service": {
"name": "vpa-webhook",
"namespace": "kube-system",
"port": 443
}
},
"failurePolicy": "Ignore",
"matchPolicy": "Equivalent",
"name": "vpa.k8s.io",
"namespaceSelector": {},
"objectSelector": {},
"reinvocationPolicy": "Never",
"rules": [
{
"apiGroups": [
""
],
"apiVersions": [
"v1"
],
"operations": [
"CREATE"
],
"resources": [
"pods"
],
"scope": "*"
},
{
"apiGroups": [
"autoscaling.k8s.io"
],
"apiVersions": [
"*"
],
"operations": [
"CREATE",
"UPDATE"
],
"resources": [
"verticalpodautoscalers"
],
"scope": "*"
}
],
"sideEffects": "None",
"timeoutSeconds": 30
}
]
}
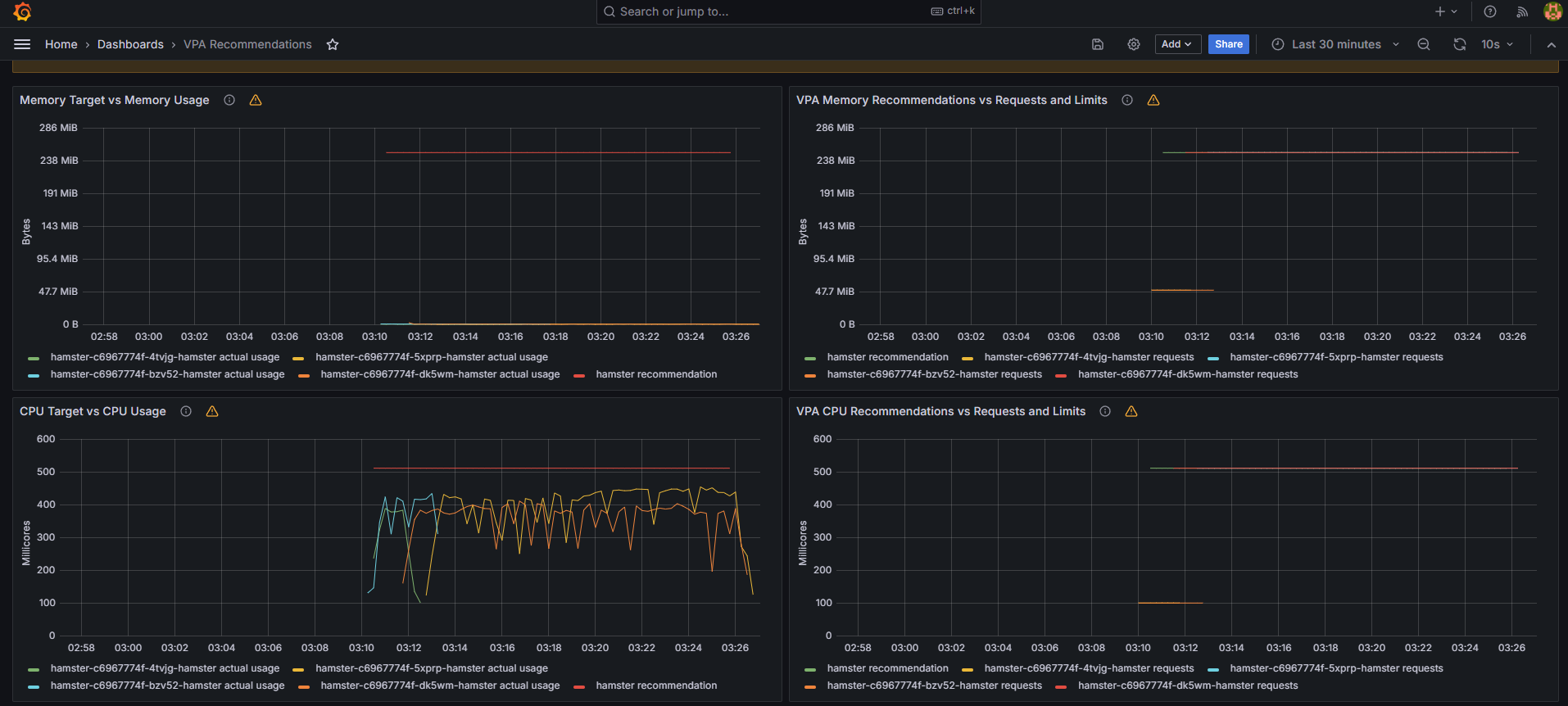
기존 파드의 스펙은 0.1Core/50Mi 이지만, 파드를 구동하기 위해서 0.5Core/260Mi 스펙이 필요합니다.
spec.updatePolicy.updateMode가 'Auto'이면 VPA가 자동으로 파드의 스펙을 변경하여 재실행합니다.
따라서 권장 스펙을 만족하는 신규 파드를 재생성한 후 기존 파드를 삭제하는 동작 과정이 이루어집니다.
그리고 쿠버네티스의 VPA 이벤트 로그를 통해 기존 파드가 축출되었음을 확인할 수 있습니다.
# VPA 공식 예제 배포
$ cd ~/autoscaler/vertical-pod-autoscaler/
$ kubectl apply -f examples/hamster.yaml && kubectl get vpa -w
NAME MODE CPU MEM PROVIDED AGE
hamster-vpa Auto 2s
hamster-vpa Auto 511m 262144k True 35s
# 파드 리소스(Request) 확인
$ kubectl describe pod | grep Requests: -A2
Requests:
cpu: 100m
memory: 50Mi
--
Requests:
cpu: 100m
memory: 50Mi
--
Requests:
cpu: 511m
memory: 262144k
--
Requests:
cpu: 511m
memory: 262144k
# 모니터링
$ watch -d "kubectl top pod;echo "----------------------";kubectl describe pod | grep Requests: -A2"
NAME CPU(cores) MEMORY(bytes)
hamster-c6967774f-4tvjg 381m 0Mi
hamster-c6967774f-bzv52 444m 0Mi
----------------------
Requests:
cpu: 100m
memory: 50Mi
--
Requests:
cpu: 100m
memory: 50Mi
--
Requests:
cpu: 511m
memory: 262144k
--
Requests:
cpu: 511m
memory: 262144k
# VPA 이벤트 로그 확인
$ kubectl get events --sort-by=".metadata.creationTimestamp" | grep VPA
3m58s Normal EvictedByVPA pod/hamster-c6967774f-4tvjg Pod was evicted by VPA Updater to apply resource recommendation.
2m58s Normal EvictedByVPA pod/hamster-c6967774f-bzv52 Pod was evicted by VPA Updater to apply resource recommendation.
* In-place Resource Resize for Kuberetes Pods
- VPA 구성없이, 파드를 재실행하지 않고 파드의 스펙을 온라인으로 변경하는 기능입니다.
- Kubernetes v1.27 (Alpha)
- 2023.05 Release
CA(Cluster Autoscaler)
퍼블릭 클라우드 환경에서 파드가 아닌 클러스터 자체를 수평 스케일링하는 방법입니다.
CA 컨트롤러는 노드의 리소스 부족으로 파드를 시작하지 못한 경우(Pending)에 노드 수를 늘립니다.
반대로 노드의 리소스 사용률이 낮은 상태로 일정 시간(기본 10분) 지속되면 해당 노드를 폐기하여 노드 수를 조정합니다.

AWS 환경에서 CA 동작 과정을 테스트합니다.
AWS에서는 Auto Scaling Group(ASG)를 사용하여 CA를 적용합니다.
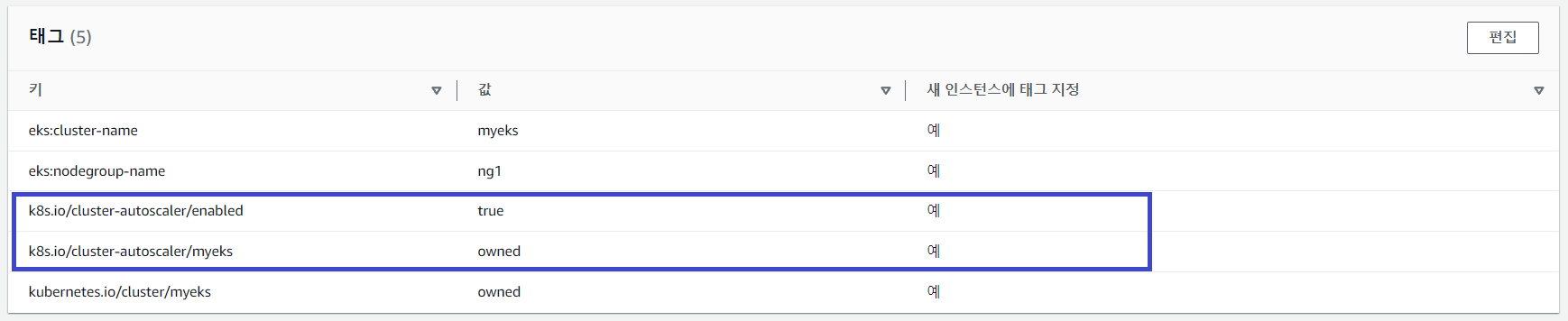
Amazon EKS는 이미 ASG를 사용하여 Worker Node를 구성하고 있습니다.
# ASG 정보 확인
$ aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-78c759d6-7874-b232-64ed-9097fb9e9e81 | 3 | 3 | 3 |
+------------------------------------------------+----+----+----+
# MaxSize=6 변경
$ export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
$ aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 6
$ aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-78c759d6-7874-b232-64ed-9097fb9e9e81 | 3 | 6 | 3 |
+------------------------------------------------+----+----+----+

CA 컨트롤러를 배포하고 구성합니다.
# CA 배포
$ curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
$ sed -i "s/<YOUR CLUSTER NAME>/$CLUSTER_NAME/g" cluster-autoscaler-autodiscover.yaml
$ kubectl apply -f cluster-autoscaler-autodiscover.yaml
serviceaccount/cluster-autoscaler created
clusterrole.rbac.authorization.k8s.io/cluster-autoscaler created
role.rbac.authorization.k8s.io/cluster-autoscaler created
clusterrolebinding.rbac.authorization.k8s.io/cluster-autoscaler created
rolebinding.rbac.authorization.k8s.io/cluster-autoscaler created
deployment.apps/cluster-autoscaler created
# CA 배포 확인
$ kubectl get pod -n kube-system | grep cluster-autoscaler
cluster-autoscaler-857b945c88-vjbt4 1/1 Running 0 18s
$ kubectl describe deployments.apps -n kube-system cluster-autoscaler | grep node-group-auto-discovery
--node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/myeks
# (옵션) cluster-autoscaler 파드가 동작하는 워커 노드가 퇴출(evict) 되지 않게 설정
$ kubectl -n kube-system annotate deployment.apps/cluster-autoscaler cluster-autoscaler.kubernetes.io/safe-to-evict="false"
deployment.apps/cluster-autoscaler annotated
이제 고스펙(0.5Core/512Mi)의 파드를 15개 정도 배포하여 CA에 의해 노드가 자동으로 생성되는지 확인합니다.
# Deployment 배포
$ cat <<EoF> nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-to-scaleout
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
service: nginx
app: nginx
spec:
containers:
- image: nginx
name: nginx-to-scaleout
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
EoF
$ kubectl apply -f nginx.yaml
deployment.apps/nginx-to-scaleout created
$ kubectl get deployment/nginx-to-scaleout
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-to-scaleout 1/1 1 1 32s
# ReplicaSet: 1 → 15 변경
$ kubectl scale --replicas=15 deployment/nginx-to-scaleout && date
deployment.apps/nginx-to-scaleout scaled
Sun Apr 7 04:36:05 KST 2024
# Worker Node 자동 증가 확인
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-192-168-1-83.ap-northeast-2.compute.internal Ready <none> 6h3m v1.28.5-eks-5e0fdde
ip-192-168-1-87.ap-northeast-2.compute.internal Ready <none> 3m21s v1.28.5-eks-5e0fdde
ip-192-168-2-108.ap-northeast-2.compute.internal Ready <none> 3m14s v1.28.5-eks-5e0fdde
ip-192-168-2-114.ap-northeast-2.compute.internal Ready <none> 6h3m v1.28.5-eks-5e0fdde
ip-192-168-3-227.ap-northeast-2.compute.internal Ready <none> 3m15s v1.28.5-eks-5e0fdde
ip-192-168-3-63.ap-northeast-2.compute.internal Ready <none> 6h3m v1.28.5-eks-5e0fdde
# ASG DesiredCapacity 값 확인
$ aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-78c759d6-7874-b232-64ed-9097fb9e9e81 | 3 | 6 | 6 |
+------------------------------------------------+----+----+----+
# 모니터링
$ kubectl get pods -l app=nginx -o wide --watch
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-to-scaleout-5f9f9c65ff-4pc46 1/1 Running 0 4m52s 192.168.1.126 ip-192-168-1-87.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-4wff9 1/1 Running 0 4m52s 192.168.2.95 ip-192-168-2-108.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-5fw7x 1/1 Running 0 4m52s 192.168.2.123 ip-192-168-2-108.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-64kgg 1/1 Running 0 4m52s 192.168.2.122 ip-192-168-2-108.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-7p77n 1/1 Running 0 4m52s 192.168.3.204 ip-192-168-3-63.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-bjlrf 1/1 Running 0 19m 192.168.1.199 ip-192-168-1-83.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-csbqj 1/1 Running 0 4m52s 192.168.2.166 ip-192-168-2-114.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-h764h 1/1 Running 0 4m52s 192.168.2.169 ip-192-168-2-114.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-ql7p9 1/1 Running 0 4m52s 192.168.3.123 ip-192-168-3-227.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-sqlj2 1/1 Running 0 4m52s 192.168.3.8 ip-192-168-3-227.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-tgmlk 1/1 Running 0 4m52s 192.168.1.77 ip-192-168-1-87.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-tqd8m 1/1 Running 0 4m52s 192.168.1.134 ip-192-168-1-83.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-whmcv 1/1 Running 0 4m52s 192.168.3.31 ip-192-168-3-227.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-zfsww 1/1 Running 0 4m52s 192.168.3.140 ip-192-168-3-63.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-5f9f9c65ff-zqzdp 1/1 Running 0 4m52s 192.168.1.203 ip-192-168-1-87.ap-northeast-2.compute.internal <none> <none>
$ kubectl -n kube-system logs -f deployment/cluster-autoscaler
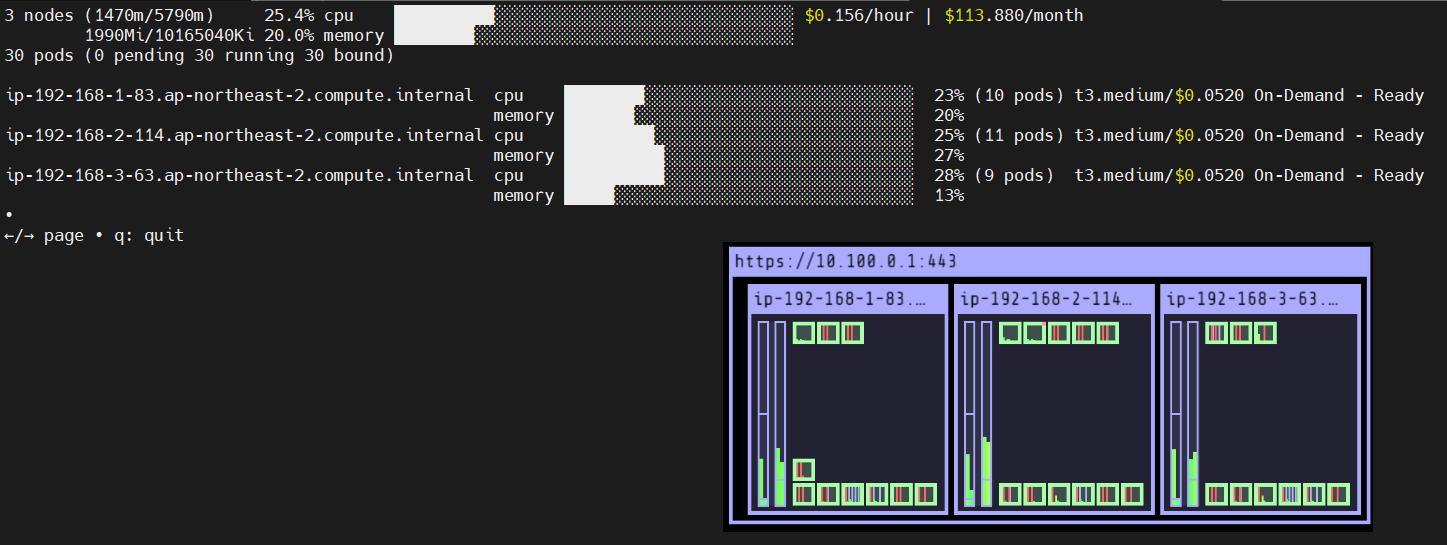
노드의 리소스가 부족하여 할당되지 못한 파드들은 Pending 상태에 빠지게 됩니다.
파드(Pending)가 할당될 신규 노드가 생성되기까지 서비스가 지연될 수 있습니다.

신규 노드가 자동으로 생성되면서 Pending 상태의 파드들이 정상적으로 배포되기 시작합니다.

이번에는 디플로이먼트를 삭제하여 노드 개수를 축소해보겠습니다.
기본적으로 10분 정도의 시간이 소요된 후 노드가 축소되는 것을 확인할 수 있습니다.
* CA 단점
- 하나의 자원에 대해서 ASG와 EKS가 각자의 방식으로 관리하므로 관리정보가 서로 동기화되지 않아 여러 문제가 발생하게 됩니다.
- CA는 ASG에만 의존하고 노드의 생성/삭제하는 작업에는 직접 관여하지 않습니다.
- 노드를 축소할 때 파드 수가 적은 노드 또는 drain된 노드를 먼저 축소하므로 특정 노드를 축소하는 것은 어렵습니다.
- 스케일링 속도가 매우 느립니다. => 대응방안: Karpenter
- 언뜻 보기에 클러스터 전체 또는 각 노드의 부하 평균이 높아졌을 때 확장되는 것으로 보입니다. (함정)
- Pending 상태의 파드가 발생하는 타이밍에 처음으로 CA가 동작합니다.
- 즉, Request와 Limit을 적절하게 설정하지 않은 상태에서 실제 노드의 부하 평균이 낮은 상황임에도 불구하고 스케일 아웃하거나, 반대로 부하 평균이 높은 상홤임에도 스케일 아웃하지 않는 현상이 발생할 수 있습니다.
- CPU와 MEM 리소스 모두 동일하게 적용될 수 있습니다.
CPA(Cluster Proportional Autoscaler)
노드 수 증가에 비례하여 성능 처리가 필요한 어플리케이션 파드를 수평으로 자동 확장하는 방법입니다.

예를 들어 노드 수량을 10개 생성할 때 coredns 파드는 3개로 제한하고, 노드 수량을 30개 생성할 때 coredns 파드는 10개로 제한하는 등의 설정을 제한할 수 있습니다.
다음은 노드가 5 대일 경우 5 개의 파드를 배포하고, 노드가 4 대일 경우 3 개의 파드를 배포하는 예시입니다.
# CPA 배포
$ helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler
"cluster-proportional-autoscaler" has been added to your repositories
$ helm upgrade --install cluster-proportional-autoscaler cluster-proportional-autoscaler/cluster-proportional-autoscaler
# nginx 디플로이먼트 배포
$ cat <<EOT > cpa-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
resources:
limits:
cpu: "100m"
memory: "64Mi"
requests:
cpu: "100m"
memory: "64Mi"
ports:
- containerPort: 80
EOT
$ kubectl apply -f cpa-nginx.yaml
# CPA 규칙 설정
$ cat <<EOF > cpa-values.yaml
config:
ladder:
nodesToReplicas:
- [1, 1]
- [2, 2]
- [3, 3]
- [4, 3]
- [5, 5]
options:
namespace: default
target: "deployment/nginx-deployment"
EOF
$ kubectl describe cm cluster-proportional-autoscaler
Name: cluster-proportional-autoscaler
Namespace: default
Labels: app.kubernetes.io/managed-by=Helm
Annotations: meta.helm.sh/release-name: cluster-proportional-autoscaler
meta.helm.sh/release-namespace: default
Data
====
ladder:
----
{"nodesToReplicas":[[1,1],[2,2],[3,3],[4,3],[5,5]]}
BinaryData
====
# helm 업그레이드
$ helm upgrade --install cluster-proportional-autoscaler -f cpa-values.yaml cluster-proportional-autoscaler/cluster-proportional-autoscaler
# 노드 5 개로 증가
$ export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
$ aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 5 --desired-capacity 5 --max-size 5
$ aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-78c759d6-7874-b232-64ed-9097fb9e9e81 | 5 | 5 | 5 |
+------------------------------------------------+----+----+----+
# [Node,Pod] = [5,5]
$ watch -d kubectl get pod
NAME READY STATUS RESTARTS AGE
cluster-proportional-autoscaler-54fbf57d9c-565cr 1/1 Running 0 2m49s
nginx-deployment-788b6c585-bxmgq 1/1 Running 0 5s
nginx-deployment-788b6c585-dgtww 1/1 Running 0 2m45s
nginx-deployment-788b6c585-qdwnc 1/1 Running 0 5s
nginx-deployment-788b6c585-vsbgz 1/1 Running 0 4m7s
nginx-deployment-788b6c585-xqq9s 1/1 Running 0 2m45s
# 노드 4 개로 축소
$ aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 4 --desired-capacity 4 --max-size 4
$ aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-78c759d6-7874-b232-64ed-9097fb9e9e81 | 4 | 4 | 4 |
+------------------------------------------------+----+----+----+
# [Node,Pod] = [4,3]
$ watch -d kubectl get pod
NAME READY STATUS RESTARTS AGE
cluster-proportional-autoscaler-54fbf57d9c-565cr 1/1 Running 0 4m17s
nginx-deployment-788b6c585-dgtww 1/1 Running 0 4m13s
nginx-deployment-788b6c585-qdwnc 1/1 Running 0 93s
nginx-deployment-788b6c585-vsbgz 1/1 Running 0 5m35s
[출처]
1) CloudNet@, AEWS 실습 스터디
2) https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
HorizontalPodAutoscaler Walkthrough
A HorizontalPodAutoscaler (HPA for short) automatically updates a workload resource (such as a Deployment or StatefulSet), with the aim of automatically scaling the workload to match demand. Horizontal scaling means that the response to increased load is t
kubernetes.io
3) https://docs.aws.amazon.com/eks/latest/userguide/horizontal-pod-autoscaler.html
Horizontal Pod Autoscaler - Amazon EKS
It may take a few minutes before you see the replica count reach its maximum. If only 6 replicas, for example, are necessary for the CPU load to remain at or under 50%, then the load won't scale beyond 6 replicas.
docs.aws.amazon.com
4) https://keda.sh/docs/2.10/concepts/
KEDA | KEDA Concepts
What KEDA is and how it works
keda.sh
5) https://devocean.sk.com/blog/techBoardDetail.do?ID=164800
쿠버네티스 KEDA 소개
devocean.sk.com
6) https://grafana.com/grafana/dashboards/14588-vpa-recommendations/
VPA Recommendations | Grafana Labs
Thank you! Your message has been received!
grafana.com
7) https://kubernetes.io/blog/2023/05/12/in-place-pod-resize-alpha/
Kubernetes 1.27: In-place Resource Resize for Kubernetes Pods (alpha)
Author: Vinay Kulkarni (Kubescaler Labs) If you have deployed Kubernetes pods with CPU and/or memory resources specified, you may have noticed that changing the resource values involves restarting the pod. This has been a disruptive operation for running w
kubernetes.io
8) https://kubernetes.io/docs/tasks/configure-pod-container/resize-container-resources/
Resize CPU and Memory Resources assigned to Containers
FEATURE STATE: Kubernetes v1.27 [alpha] This page assumes that you are familiar with Quality of Service for Kubernetes Pods. This page shows how to resize CPU and memory resources assigned to containers of a running pod without restarting the pod or its co
kubernetes.io
Amazon EKS web application workshop
Building simple web application using Amazon EKS. This workshop covers from creating eks cluster to application's life cycle.
catalog.us-east-1.prod.workshops.aws
10) https://www.eksworkshop.com/docs/autoscaling/workloads/cluster-proportional-autoscaler/
Cluster Proportional Autoscaler | EKS Workshop
Scale workloads proportional to the size of your Amazon Elastic Kubernetes Service cluster with Cluster Proportional Autoscaler.
www.eksworkshop.com
'AWS > EKS' 카테고리의 다른 글
| [AEWS2] 6-1. JWT 란? (0) | 2024.04.13 |
|---|---|
| [AEWS2] 5-2. Karpenter (1) | 2024.04.07 |
| [AEWS2] 4-2. Prometheus & Grafana (0) | 2024.03.31 |
| [AEWS2] 4-1. EKS Observability (0) | 2024.03.31 |
| [AEWS2] 3-1. EKS Storage & Nodegroup (1) | 2024.03.24 |



