



✍ Posted by Immersive Builder Seong
1. BPF/eBPF
BPF (Berkeley Packet Filter)
BPF는 네트워크 패킷을 효율적으로 캡처하고 필터링하기 위한 목적으로 개발된 기술입니다. BPF는 커널 수준에서 Hook을 통해 패킷을 통제하고, 다양한 영역에서 커널 내부의 데이터를 처리할 수 있습니다.

eBPF (extended BPF)
기존 BPF를 확장한 기술로 네트워크 필터링 뿐만 아니라 추적, 모니터링, 보안 기능을 제공합니다. 커널 소스를 수정하거나 커널 모듈을 적재하지 않고 커널 샌드박스 내에서 동적으로 프로그래밍하고 실행합니다.
● 주요 기능 : Networking, Tracing & Profiling, Observability, Security

● 구성 요소
- BPF Program : 사용자가 작성하여 커널에 로드하는 작은 코드 조각으로 커널에 특정 기능을 추가하거나 수정할 수 있도록 설계되어 있으며, eBPF Bytecode로 컴파일하여 커널에 로드합니다.
- BPF Map : 데이터를 저장하고 조회할 수 있는 커널 내부의 자료 구조로, eBPF Program과 User Space Program 간 데이터를 공유하는 데 사용됩니다.
- BPF Link : eBPF Program을 커널의 특정 위치에 연결하는 역할을 합니다.
- Kernel Hook : Hook을 통해 eBPF Program을 호출하고 커널에서 발생하는 이벤트를 감시하거나 조작합니다.
- BPF Tool Chain : LLVM/Clang, BCC(BPF Compiler Collection), bpftool, bpftrace 등의 도구를 사용하여 eBPF Program을 작성하고 실행합니다.
● 동작 과정
eBPF가 리눅스 커널에 내장되어 프로세스에서 시스템콜을 호출할 때 User Space 영역을 거치지 않고 동작합니다. eBPF Hook은 Syscall, Sockets, TCP/IP, Network Device 등 모든 계층에 연결될 수 있습니다. 전통적인 리눅스 네트워크 스택은 복잡하고 변경에 시간이 소요될 뿐만 아니라 각 계층을 건너뛰기 어려운 반면, eBPF는 netfilter~L4~L7 계층을 모두 건너뛰고 통신하므로 네트워크 성능이 매우 좋습니다.

XDP (eXpress Data Path)
XDP는 네트워크 패킷 처리를 위해 eBPF를 활용하는 프레임워크입니다. 네트워크 인터페이스 카드로 들어오는 패킷을 커널의 네트워크 스택에 도달하기 전에 직접 처리합니다. XDP는 CPU 사용률을 낮추고 네트워크 성능을 향상시킬 수 있지만, 네트워크 인터페이스 카드와 드라이버가 XDP를 지원해야 하는 의존성이 존재합니다.
● XDP 모드
- Generic XDP : 리눅스 커널 네트워크 스택에서 동작하는 모드로 NIC가 XDP를 지원하지 않는 경우 사용합니다.
- Native XDP : 네트워크 인터페이스 드라이버에 XDP가 적용되는 모드입니다.
- Offloaded XDP : 네트워크 인터페이스 카드의 하드웨어에서 XDP Program이 실행되는 모드입니다. CPU 부하를 줄이고 성능을 극대화할 수 있습니다.

● 계층(구간)별 패킷 차단 비교
2019년 Kosslab에서 발표한 연구 결과에 따르면 XDP> TC> Netfilter> User Space 순으로 성능이 측정되었습니다. XDP는 User Space 보다 약 12배 이상 성능이 뛰어나며, 특히 Offloaded XDP 모드를 적용하였을 때 NIC의 네트워크 성능을 거의 의 그대로 출력하는 결과(10Gbit/s)를 보여주었습니다.

2. Cilium CNI
Cilium CNI
Cilium은 eBPF를 기반으로 파드 네트워크 및 보안 환경을 제공하는 CNI 플러그인입니다. Cilium은 수신 NIC의 ingress TC Hook을 통해 모든 패킷을 가져옵니다. * TC(Traffic Control): 커널에서 동작하는 패킷 스케줄러

● 주요 특징
- eBPF 기반 네트워크 : IPtables를 사용하지 않고 eBPF를 활용해 네트워크 트래픽을 커널 단에서 직접 처리합니다.
- L3/L4/L7 레벨의 네트워크 정책 : L3 부터 L7 레벨까지 다양한 네트워크 정책을 적용할 수 있습니다.
- 고성능 : User Space 영역과 커널 영역 간 Context Switching을 최소화하여 고성능의 네트워크를 제공합니다.
- 서비스 메시 통합 : 네이티브 서비스 메시 기능을 제공하며, Envoy와 같은 프록시와 통합되어 서비스 간 통신을 모니터링하고 관리합니다. Istio 등 기존 서비스 메시 솔루션과 통합이 가능합니다.
- 로드밸런싱 : 네트워크 패킷을 지능적으로 라우팅하고, 쿠버네티스 서비스 및 엔드포인트로의 로드밸런싱 기능을 제공합니다.
- DSR 및 Maglev Hashing 등 고급 로드밸런싱 알고리즘을 지원합니다.
- eBPF 장애 시, IPtables가 대체 동작하도록 규칙이 설정되어 있습니다. 필요 시, IPtables와 eBPF를 하이브리드로 혼용할 수 있습니다.
● 구성 요소
- Cilium Agent : 데몬셋으로 실행되며, 네트워크 정책을 관리하고 eBPF 프로그램을 적재합니다.
- Cilium CLI : Cilium을 관리하고 설정할 수 있는 CLI로 eBPF Maps에 직접 접속하여 상태를 확인합니다.
- Cilium Operator : 쿠버네티스 클러스터의 상태를 관리하고 노드 간 네트워크 연결을 설정합니다.
- Hubble : Cilium 자체 모니터링 도구로 Server, Relay, Client, Graphical UI로 구성됩니다.
- Data Store : Cilium Agent 간의 상태를 저장하고 전파하는 데이터 저장소입니다. ex) K8S CRDs, Key-Value Store 택1

● 네트워크 모드
- Tunnel 모드 : VXLAN(UDP 8472) / Geneve(UDP 6081) Encapsulation
- Native-routing 모드 : CSP 라우터 또는 BGP 라우팅 프로토콜을 사용하여 패킷 캡슐화 없이 직접 통신합니다.

eBPF Datapath
eBPF Datapath는 네트워크 트래픽을 처리하기 위해 eBPF 기술을 사용하는 네트워크 경로를 의미합니다. eBPF Datapath는 전통적인 커널 네트워크 스택을 우회하여, 커널 수준에서 패킷을 효율적으로 처리하고 사용자 정의 로직을 적용할 수 있도록 해줍니다.
● eBPF Hooks
- XDP : 네트워크 인터페이스 드라이버 앞단에서 BPF XDP Hook을 통해 BPF Program을 트리거하므로 최상의 성능을 제공합니다.
- TC : 파드와 연결된 veth pair의 lxc 인터페이스의 BPF TC ingress Hook을 통해 BPF Program을 트리거합니다.
- Socket operations : root cgroup에 연결되며 TCP event(ESTABLISHED)에서 트리거됩니다.
- Socket send/recv : TCP socket의 모든 송수신 작업에서 트리거되어 Hook에서 검사/삭제/리다이렉션할 수 있습니다.
- Endpoint Policy : 정책에 따라 패킷을 차단/전달하거나 서비스 또는 L7 정책을 전달할 수 있습니다.
- Service : 모든 패킷의 목적지 IP/Port의 map 조회 시 일치하면 L3/L4 endpoint 로 전달하며, Service block은 모든 인터페이스의 TC ingress Hook에서 동작할 수 있습니다.
- L7 Policy : L7 정책을 User Space 영역의 Envoy 프록시 서버로 리다이렉트할 수 있습니다.
● Life of a Packet
- Endpoint to Endpoint

- Egress from Endpoint

- Ingress to Endpoint

● eBPF Maps
모든 eBPF Map은 Max Limit이 있으며, Limit을 초과할 시 eBPF Datapath 확장이 제한됩니다.
| Connection Tracking | node or endpoint | 1M TCP/256k UDP | Max 1M concurrent TCP connections, max 256k expected UDP answers |
| NAT | node | 512k | Max 512k NAT entries |
| Neighbor Table | node | 512k | Max 512k neighbor entries |
| Endpoints | node | 64k | Max 64k local endpoints + host IPs per node |
| IP cache | node | 512k | Max 256k endpoints (IPv4+IPv6), max 512k endpoints (IPv4 or IPv6) across all clusters |
| Load Balancer | node | 64k | Max 64k cumulative backends across all services across all clusters |
| Policy | endpoint | 16k | Max 16k allowed identity + port + protocol pairs for specific endpoint |
| Proxy Map | node | 512k | Max 512k concurrent redirected TCP connections to proxy |
| Tunnel | node | 64k | Max 32k nodes (IPv4+IPv6) or 64k nodes (IPv4 or IPv6) across all clusters |
| IPv4 Fragmentation | node | 8k | Max 8k fragmented datagrams in flight simultaneously on the node |
| Session Affinity | node | 64k | Max 64k affinities from different clients |
| IP Masq | node | 16k | Max 16k IPv4 cidrs used by BPF-based ip-masq-agent |
| Service Source Ranges | node | 64k | Max 64k cumulative LB source ranges across all services |
| Egress Policy | endpoint | 16k | Max 16k endpoints across all destination CIDRs across all clusters |
Kube-proxy는 코어 수에 따라 CT Table의 최대 항목 개수가 결정되지만, Cilium은 자체 BPF Maps를 사용하고 메모리 용량에 따라 최대 항목 개수가 결정됩니다.
| vCPU | Memory (GiB) | Kube-proxy CT entries | Cilium CT entries |
| 1 | 3.75 | 131072 | 131072 |
| 2 | 7.5 | 131072 | 131072 |
| 4 | 15 | 131072 | 131072 |
| 8 | 30 | 262144 | 284560 |
| 16 | 60 | 524288 | 569120 |
| 32 | 120 | 1048576 | 1138240 |
| 64 | 240 | 2097152 | 2276480 |
| 96 | 360 | 3145728 | 4552960 |
Cilium 배포
# Cilium CNI 설치
$ helm repo add cilium https://helm.cilium.io/
$ helm repo update
$ helm install cilium cilium/cilium --version 1.16.3 --namespace kube-system \
--set k8sServiceHost=192.168.10.10 --set k8sServicePort=6443 --set debug.enabled=true \
--set rollOutCiliumPods=true --set routingMode=native --set autoDirectNodeRoutes=true \
--set bpf.masquerade=true --set bpf.hostRouting=true --set endpointRoutes.enabled=true \
--set ipam.mode=kubernetes --set k8s.requireIPv4PodCIDR=true --set kubeProxyReplacement=true \
--set ipv4NativeRoutingCIDR=192.168.0.0/16 --set installNoConntrackIptablesRules=true \
--set hubble.ui.enabled=true --set hubble.relay.enabled=true --set prometheus.enabled=true --set operator.prometheus.enabled=true --set hubble.metrics.enableOpenMetrics=true \
--set hubble.metrics.enabled="{dns:query;ignoreAAAA,drop,tcp,flow,port-distribution,icmp,httpV2:exemplars=true;labelsContext=source_ip\,source_namespace\,source_workload\,destination_ip\,destination_namespace\,destination_workload\,traffic_direction}" \
--set operator.replicas=1
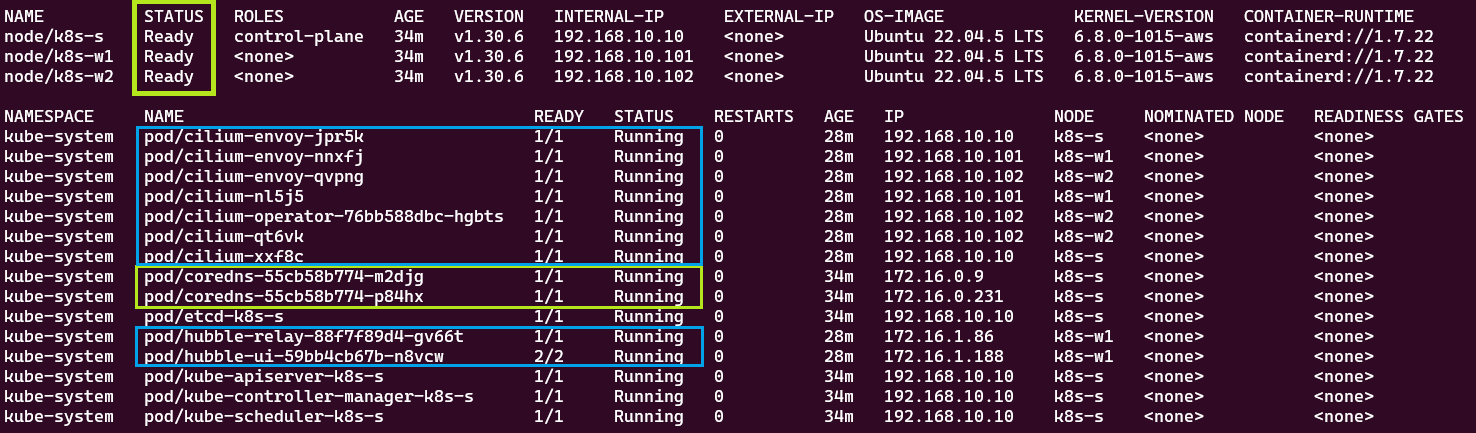



Cilium CLI 설치
# Cilium CLI 설치
$ CILIUM_CLI_VERSION=$(curl -s https://raw.githubusercontent.com/cilium/cilium-cli/main/stable.txt)
$ CLI_ARCH=amd64
$ if [ "$(uname -m)" = "aarch64" ]; then CLI_ARCH=arm64; fi
$ curl -L --fail --remote-name-all https://github.com/cilium/cilium-cli/releases/download/${CILIUM_CLI_VERSION}/cilium-linux-${CLI_ARCH}.tar.gz{,.sha256sum}
$ sha256sum --check cilium-linux-${CLI_ARCH}.tar.gz.sha256sum
$ sudo tar xzvfC cilium-linux-${CLI_ARCH}.tar.gz /usr/local/bin
$ rm cilium-linux-${CLI_ARCH}.tar.gz{,.sha256sum}


Hubble
Cilium에서 제공하는 네트워크 관찰 및 모니터링 도구로, 쿠버네티스 클러스터 내부의 네트워크 트래픽을 실시간으로 모니터링하고 분석할 수 있습니다. Hubble은 eBPF 기술을 활용하여 커널 레벨에서 패킷을 관찰하므로 높은 성능과 세밀한 가시성을 제공합니다.
- 어플리케이션의 코드 수정 등 추가 설정 없이 동작합니다.
- 컨테이너 워크로드뿐만 아니라 VM/Serve 모니터링도 지원합니다.
- 전통적인 IP 기반의 모니터링/통제가 아니라 서비스/파드/ID 기반으로 모니터링/통제를 제공합니다.
- Hubble CLI를 사용하여 로컬 Unix Domain Socket을 통해 제공된 Hubble API를 쿼리할 수 있습니다. Hubble CLI 바이너리는 기본적으로 Cilium Agent 파드에 설치됩니다.
- Hubble Relay를 배포하면 전체 클러스터 또는 ClusterMesh에 대한 네트워크 가시성을 제공합니다.


Hubble CLI 설치
# Install Hubble Client
$ HUBBLE_VERSION=$(curl -s https://raw.githubusercontent.com/cilium/hubble/master/stable.txt)
$ HUBBLE_ARCH=amd64
$ if [ "$(uname -m)" = "aarch64" ]; then HUBBLE_ARCH=arm64; fi
$ curl -L --fail --remote-name-all https://github.com/cilium/hubble/releases/download/$HUBBLE_VERSION/hubble-linux-${HUBBLE_ARCH}.tar.gz{,.sha256sum}
$ sha256sum --check hubble-linux-${HUBBLE_ARCH}.tar.gz.sha256sum
$ sudo tar xzvfC hubble-linux-${HUBBLE_ARCH}.tar.gz /usr/local/bin
$ rm hubble-linux-${HUBBLE_ARCH}.tar.gz{,.sha256sum}
# Hubble API Access: localhost 4245/TCP Relay를 통해 접근
$ cilium hubble port-forward &

노드 간 파드 통신 테스트
- 파드 배포
apiVersion: v1
kind: Pod
metadata:
name: netpod
labels:
app: netpod
spec:
nodeName: k8s-s
containers:
- name: netshoot-pod
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
---
apiVersion: v1
kind: Pod
metadata:
name: webpod1
labels:
app: webpod
spec:
nodeName: k8s-w1
containers:
- name: container
image: traefik/whoami
terminationGracePeriodSeconds: 0
---
apiVersion: v1
kind: Pod
metadata:
name: webpod2
labels:
app: webpod
spec:
nodeName: k8s-w2
containers:
- name: container
image: traefik/whoami
terminationGracePeriodSeconds: 0

- Hubble WEB UI를 통한 파드의 ARP 동작 확인


서비스 통신 테스트
● Socket-Based LoadBalancing
파드 내 어플리케이션에서 소켓 통신할 때 소켓 훅을 통해 eBPF Program을 호출하여 목적지 주소를 바로 백엔드 주소로 설정합니다. 이후 소켓을 통해 송신되는 패킷들은 DNAT 변환과 CT Table 저장이 필요없게 됩니다.
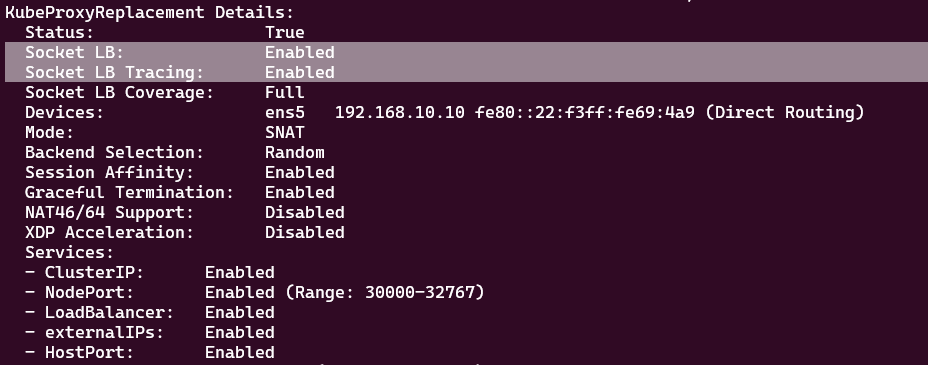
- 서비스 배포
apiVersion: v1
kind: Service
metadata:
name: svc
spec:
ports:
- name: svc-webport
port: 80
targetPort: 80
selector:
app: webpod
type: ClusterIP

- 서비스 접속 및 패킷 분석
$ kubectl exec netpod -- curl -s 10.10.12.243
서비스로 전달되는 패킷은 서비스의 IP 주소가 아닌 목적지 파드의 IP 주소로 바로 통신하고 있습니다.


$ kubectl exec netpod -- strace -s 65535 -f -tt curl -s $SVCIP

※ 소켓 기반 로드밸런싱 사용 시, Istio(EnvoyProxy)와 같은 사이드카를 우회하는 문제가 발생할 수 있습니다.
이런 경우 해당 기능을 파드 네임스페이스에서는 사용하지 않고, 오직 호스트 네임스페이스에서만 사용할 수 있도록 옵션을 설정할 수 있습니다. (--set hostServices.hostNamespaceOnly=true)
Prometheus & Grafana
# Prometheus Stack 배포
$ kubectl apply -f https://raw.githubusercontent.com/cilium/cilium/1.16.3/examples/kubernetes/addons/prometheus/monitoring-example.yaml
$ kubectl get all -n cilium-monitoring
# 배포 확인
$ kubectl get pod,svc,ep -o wide -n cilium-monitoring
# NodePort 설정
$ kubectl patch svc grafana -n cilium-monitoring -p '{"spec": {"type": "NodePort"}}'
$ kubectl patch svc prometheus -n cilium-monitoring -p '{"spec": {"type": "NodePort"}}'
# Prometheus 웹 접속 정보 확인
$ PPT=$(kubectl get svc -n cilium-monitoring prometheus -o jsonpath={.spec.ports[0].nodePort})
$ echo -e "Prometheus URL = http://$(curl -s ipinfo.io/ip):$PPT"
# Grafana 웹 접속
$ GPT=$(kubectl get svc -n cilium-monitoring grafana -o jsonpath={.spec.ports[0].nodePort})
$ echo -e "Grafana URL = http://$(curl -s ipinfo.io/ip):$GPT"

Network Policy
Cilium CNI는 L3, L4, L7 계층의 네트워크 정책을 지원합니다.
- ID 기반 : 파드, 네임스페이스 등 레이블을 지정하여 엔드포인트 간 트래픽을 제어합니다. (L3)
- PORT 기반 : 특정 포트를 지정하여 ingress/egress 트래픽을 제어합니다. (L4)
- HTTP 기반 : URL, Path를 기반으로 매칭 허용/비허용을 구분하여 트래픽을 제어합니다. (L7)

Network Policy Hands-on
- 디플로이먼트(deathstar), 파드(tiefighter, xwing), 서비스(service/deathstar) 배포



xwing, tiefighter 파드에서 deathstar 서비스로 정상 연결이 됩니다.

- L3/L4 Network Policy

apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "rule1"
spec:
description: "L3-L4 policy to restrict deathstar access to empire ships only"
endpointSelector:
matchLabels:
org: empire
class: deathstar
ingress:
- fromEndpoints:
- matchLabels:
org: empire
toPorts:
- ports:
- port: "80"
protocol: TCP

정책에 따라 deathstar 서비스는 "Org:empire" Label을 가진 오브젝트만 ingress 트래픽을 허용합니다.
따라서 레이블 조건을 충족하지 않는 xwing 파드로부터의 서비스 접근은 거부됩니다. (Policy denied)
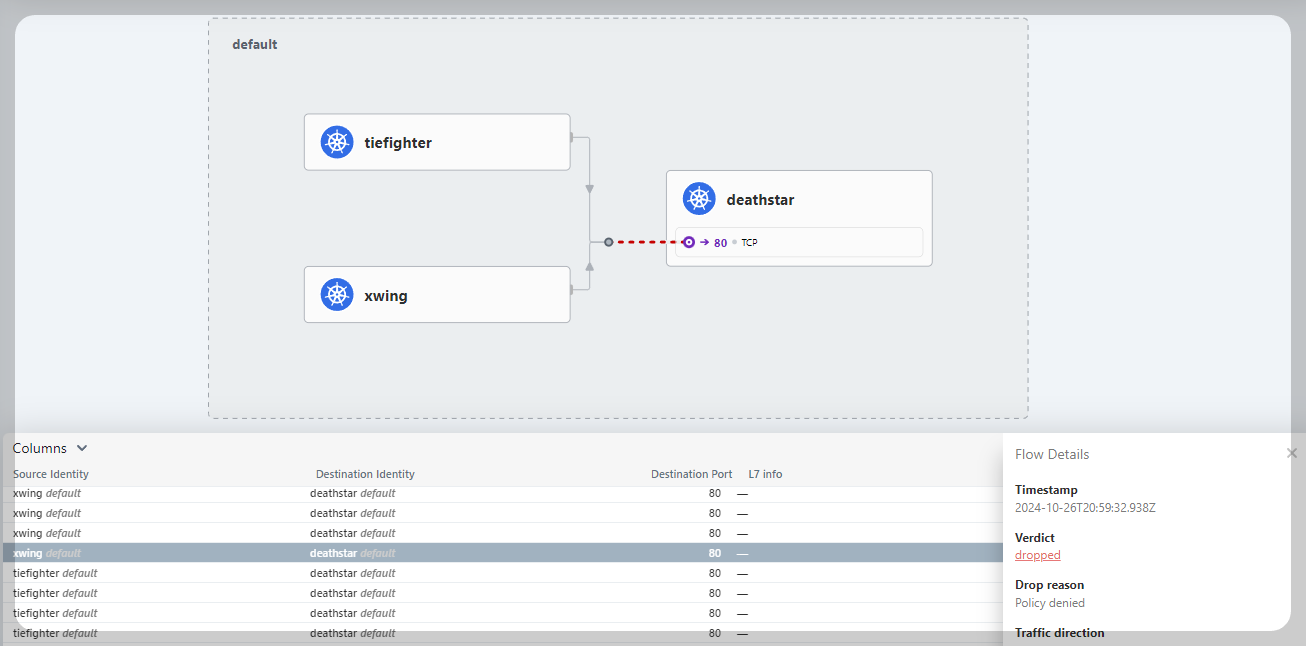

- HTTP Aware L7 Network Policy
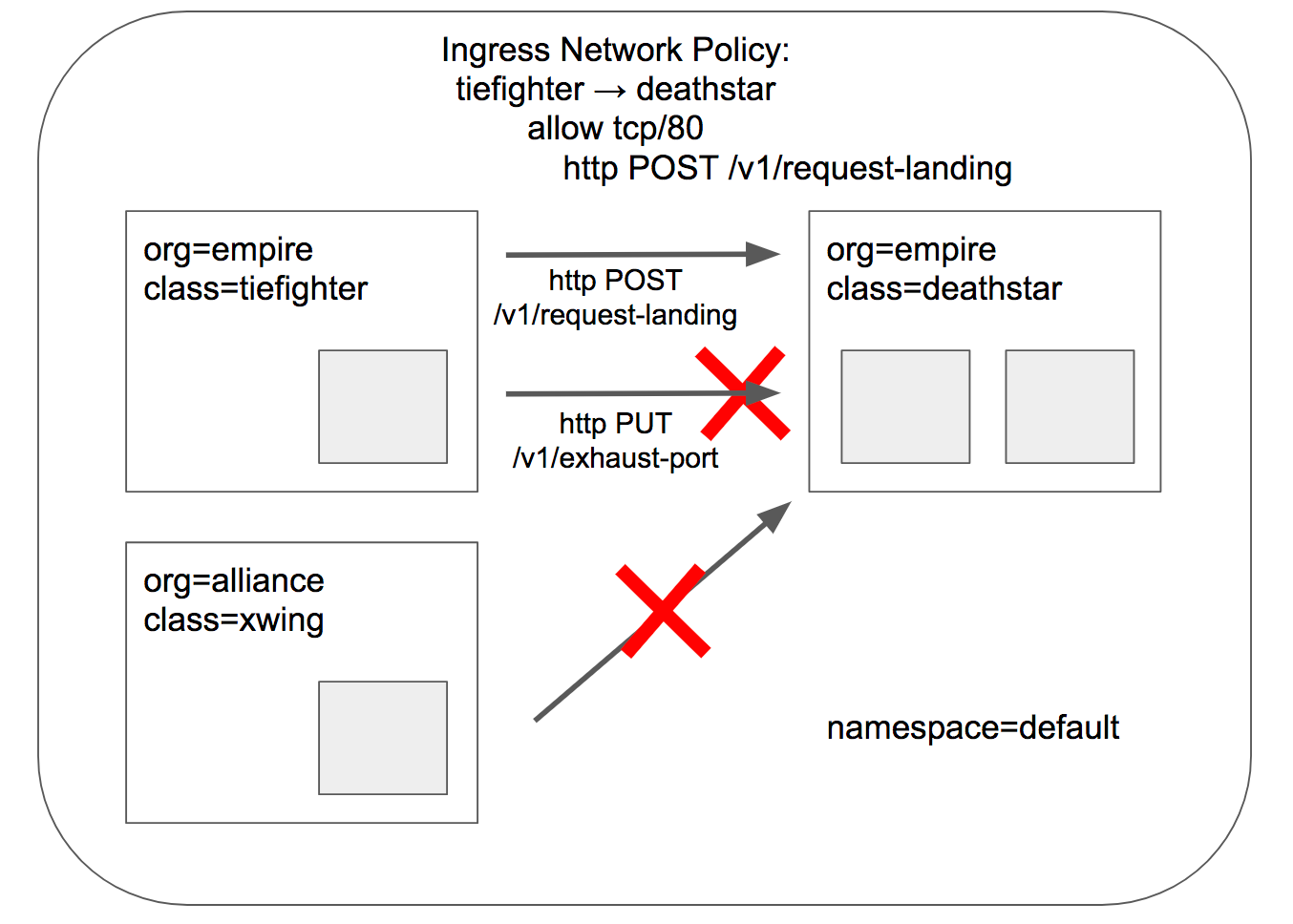
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "rule1"
spec:
description: "L7 policy to restrict access to specific HTTP call"
endpointSelector:
matchLabels:
org: empire
class: deathstar
ingress:
- fromEndpoints:
- matchLabels:
org: empire
toPorts:
- ports:
- port: "80"
protocol: TCP
rules:
http:
- method: "POST"
path: "/v1/request-landing"

기존 L3/L4 정책에 HTTP 기반 규칙이 추가되어 요청 URL에 "/v1/request-landing" Path가 존재해야 트래픽을 허용합니다.


Bandwidth Manager
Cilium CNI는 네트워크 대역폭 및 지연 시간을 최적화하기 위한 기능을 제공합니다. 대역폭의 경우 현재 egress-bandwidth만 annotation으로 지원합니다.

- Bandwidth Manager 옵션 활성화
$ helm upgrade cilium cilium/cilium --namespace kube-system --reuse-values --set bandwidthManager.enabled=true

- egress-bandwidth: 10M


- egress-bandwidth: 5M


- egress-bandwidth: 20M


L2 Announcements / L2 Aware LB
L2 Announcements는 로컬 영역 네트워크에서 서비스를 표시하고 도달 가능하게 만드는 기능입니다. 이 기능은 주로 사무실 또는 캠퍼스 네트워크와 같이 BGP 기반 라우팅이 없는 네트워크 내에서 온프레미스 배포를 위해 고안되었습니다. 이 기능을 사용하면 ExternalIP 또는 LoadBalancer IP에 대한 ARP 쿼리에 응답합니다. 이러한 IP는 여러 노드의 가상 IP이므로 각 서비스에 대해 한 번에 한 노드가 ARP 쿼리에 응답하고 MAC 주소로 응답합니다. 이 노드는 서비스 로드 밸런싱 기능으로 로드 밸런싱을 수행하여 북쪽/남쪽 로드 밸런서 역할을 합니다. NodePort 서비스에 비해 각 서비스가 고유한 IP를 사용할 수 있으므로 여러 서비스가 동일한 포트를 사용 가능한 부분이 장점입니다. NodePort를 사용할 때 트래픽을 보낼 호스트를 결정하는 것은 클라이언트에게 달려 있으며, 노드가 다운되면 IP+Port 콤보를 사용할 수 없게 됩니다. L2 Announcements를 사용하면 서비스 VIP가 다른 노드로 간단히 마이그레이션되고 계속 작동합니다.
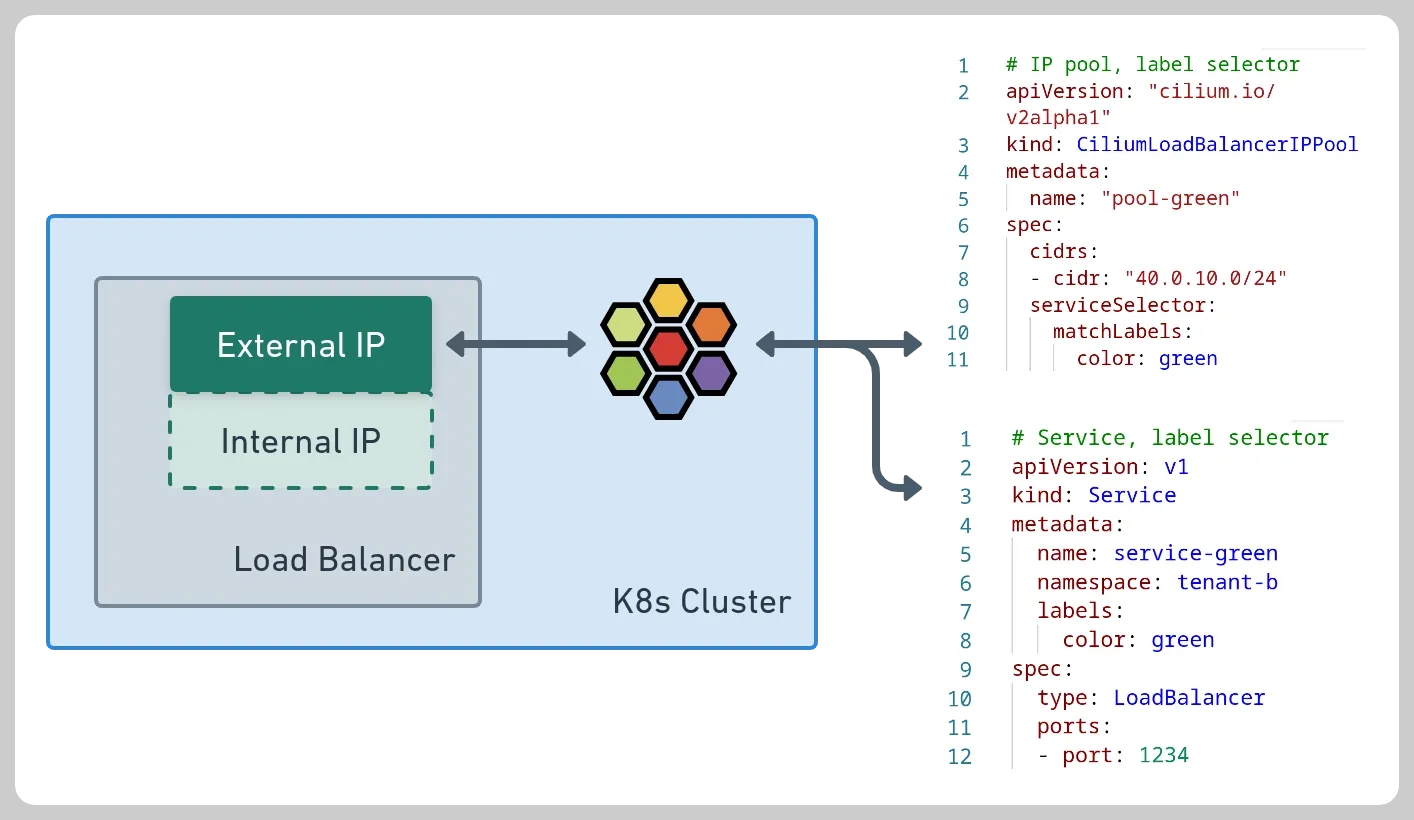
- L2 Announcements 옵션 활성화
helm upgrade cilium cilium/cilium --namespace kube-system --reuse-values \ --set l2announcements.enabled=true --set externalIPs.enabled=true \ --set l2announcements.leaseDuration=3s --set l2announcements.leaseRenewDeadline=1s --set l2announcements.leaseRetryPeriod=200ms

- Cilium L2 Announcements 생성
apiVersion: "cilium.io/v2alpha1"
kind: CiliumL2AnnouncementPolicy
metadata:
name: policy1
spec:
serviceSelector:
matchLabels:
color: blue
nodeSelector:
matchExpressions:
- key: node-role.kubernetes.io/control-plane
operator: DoesNotExist
interfaces:
- ^ens[0-9]+
externalIPs: true
loadBalancerIPs: true

- Cilium LoadBalancer IPPool 생성
apiVersion: "cilium.io/v2alpha1"
kind: CiliumLoadBalancerIPPool
metadata:
name: "cilium-pool"
spec:
allowFirstLastIPs: "No"
blocks:
- cidr: "10.10.200.0/29"

- 파드, 서비스 배포
apiVersion: v1
kind: Pod
metadata:
name: webpod1
labels:
app: webpod
spec:
nodeName: k8s-w1
containers:
- name: container
image: traefik/whoami
terminationGracePeriodSeconds: 0
---
apiVersion: v1
kind: Pod
metadata:
name: webpod2
labels:
app: webpod
spec:
nodeName: k8s-w2
containers:
- name: container
image: traefik/whoami
terminationGracePeriodSeconds: 0
---
apiVersion: v1
kind: Service
metadata:
name: svc1
spec:
ports:
- name: svc1-webport
port: 80
targetPort: 80
selector:
app: webpod
type: LoadBalancer
---
apiVersion: v1
kind: Service
metadata:
name: svc2
spec:
ports:
- name: svc2-webport
port: 80
targetPort: 80
selector:
app: webpod
type: LoadBalancer
---
apiVersion: v1
kind: Service
metadata:
name: svc3
spec:
ports:
- name: svc3-webport
port: 80
targetPort: 80
selector:
app: webpod
type: LoadBalancer

- 서비스 접속 테스트

Egress Gateway
내부망에서 외부망으로 통신할 때 Egress Gateway를 활성화하여 Soure IP를 고정합니다. 즉, 내부 어플리케이션 파드에서 외부로 나가는 과정에서 네트워크 인터페이스 카드의 IP로 SNAT하여 통신하는 방식입니다. 이 방식을 통해 방화벽 설정을 특정 IP로 고정할 수 있고, 내부 IP를 노출하지 않아도 됩니다.

[출처]
1) CloudNet@, KANS 실습 스터디
eBPF - Introduction, Tutorials & Community Resources
eBPF is a revolutionary technology that can run sandboxed programs in the Linux kernel without changing kernel source code or loading a kernel module.
ebpf.io
Cilium - Cloud Native, eBPF-based Networking, Observability, and Security
Cloud Native, eBPF-based Networking, Observability, and Security
cilium.io
'K8s > Advanced Network' 카테고리의 다른 글
| KANS3 스터디 완주 후기 (6) | 2024.11.04 |
|---|---|
| [KANS3] 9. VPC CNI (4) | 2024.11.03 |
| [KANS3] 7. Service Mesh: Istio (0) | 2024.10.20 |
| [KANS3] 6. Ingress + Gateway API (0) | 2024.10.13 |
| [KANS3] 5. MetalLB + IPVS (0) | 2024.10.06 |



